

1.2 임베딩의 역할
임베딩은 다음 역할을 수행할 수 있다
- 단어/문장 간 관련도 계산
- 의미적/문법적 정보 함축
- 전이 학습
1.2.1 단어/문장 간 관련도 계산
현업에서는 2013년 구글 연구 팀이 발표한 Word2Vec이라는 기법이 대표적이다.
단어들을 벡터로 바꾸는 방법이다.
한국어 위키백과, KorQuAD, 네이버 영화 리뷰 말뭉치 등은 은전한닢으로 형태소 분석을 한 뒤 100차원으로 학습한 Word2Vec 임베딩 중 희망 이라는 단어의 벡터는 다음과 같다
[-0.00209 -0.03918 0.02419 … 0.01715 -0.04975 0.009300]
위 수식의 숫자들은 모두 100개이다. 100차원으로 임베딩을 했기 때문이다.
단어를 벡터로 임베딩하는 순간 단어 벡터들 사이의 유사도 similarity를 계산하는 일이 가능해진다.
각 쿼리 단어별로 벡터 간 유사도 측정 기법의 일종인 코사인 유사도 cosine similarity 기준 상위 4개
| 희망 | 절망 | 학교 | 학생 |
|---|---|---|---|
| 소망 | 체념 | 초등 | 대학생 |
| 희망찬 | 절망감 | 중학교 | 대학원생 |
| 꿈 | 상실감 | 야학교 | 교직원 |
| 열망 | 번민 | 중학 | 학부모 |
희망과 코사인 유사도가 가장 높은 것은 소망이다.
자연어일 때는 불가능했던 코사인 유사도 계산이 임베딩 덕분에 가능해 졌다.
다음은 Word2Vec 임베딩을 통해서 단어 쌍 간 코사인 유사도를 시각화 한 것이다. 검정색일 수록 코사인 유사도가 높다
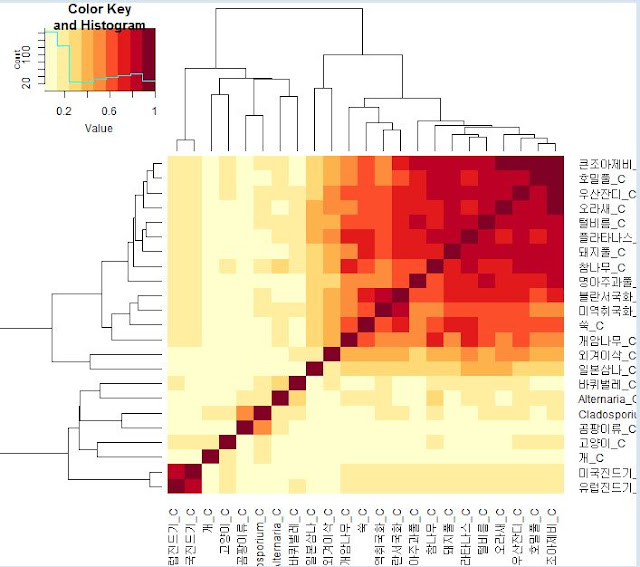
입베딩을 수행하면 벡터 공간을 기하학적으로 나타낸 시각화 역시 가능하다
1.2.2 의미/문법 정보 함축
입베딩은 벡터인 만큼 사칙연산이 가능하다.
단어 벡터간 덧셈/뺄셈을 통해 단어들 사이의 의미적, 문법적 관계를 도출해낼 수 있다.
단어 유추 평가 word analogy test
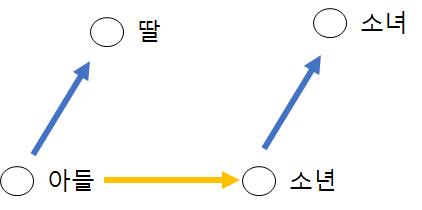
단어1 - 단어2 + 단어3 연산을 수행한 벡터와 코사인 유사도가 가장 높은 단어4를 배열한다
| 단어1 | 단어2 | 단어3 | 단어4 |
|---|---|---|---|
| 아들 | 딸 | 소년 | 소녀 |
| 아들 | 딸 | 아빠 | 엄마 |
| 아들 | 딸 | 남성 | 여성 |
| 남동생 | 여동생 | 소년 | 소녀 |
| 남동생 | 여동생 | 아빠 | 엄마 |
1.2.3 전이학습
임베딩은 다른 딥러닝 모델의 입력값으로 자주 쓰인다. 문서 분류를 위한 딥러닝 모델을 만든다.
예컨데 품질 좋은 임베딩을 쓰면 문서 분류 정확도와 학습 속도가 올라간다. 이렇게 임베딩을 다른 딥러닝 모델의 입력값으로 쓰는 기법을 전이 학습 transfer learning 이라고 한다.
전이학습
전이 학습 모델은 제로부터 시작하지 않는다. 대규모 말뭉치를 활용해 임베딩을 미리 만들어 놓는다. 임베딩에는 의미적, 문법적 정보 등이 있다.
문장의 극성을 예측하는 모델
- 양방향 LSTM에 어텐션 메커니즘을 적용
- bidirectional Long Short-Term Memory, Attention
이 딥러닝의 모델의 입력값은 FastText 임베딩(100차원)을 사용했다.
FastText 임베딩은 Word2Vec의 개선된 버전이며 59만 건에 이르는 한국어 문서를 미리 학습한 모델
학습 데이터는 다음과 같다
- 이 영화 꿀잼 + 긍정 positive
- 이 영화 노잼 + 부정 negative
전이 학습 모델은 문장을 입력받으면 해당 문장이 긍정인지 부정인지를 출력한다. 문장을 형태소 분석한 뒤 각각의 형태소에 해당하는 FastText 단어 임베딩이 모델의 입력값이 된다.


위의 그래프로 처음 부터 하는 것 보다 FastText 임베딩을 사용한 모델의 성능이 좋다. 즉, 임베딩의 품질이 좋으면 수행하려는 Task의 성능 역시 올라간다.