

물리데이터베이스
1. 물리 데이터 모델 품질 기준
- 데이터베이스 성능 향상과 오류 예방
- 품질 기준
- 정확성
- 완전성
- 준거성
- 최신성
- 일관성
- 활용성
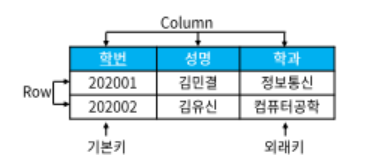
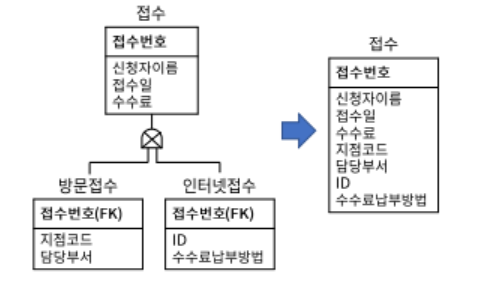
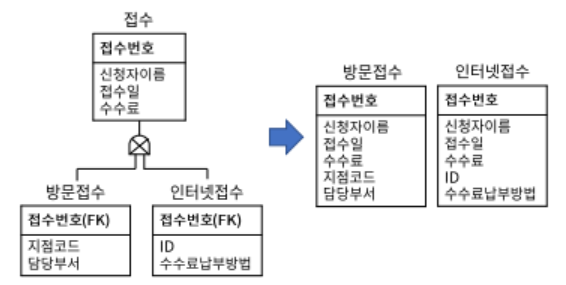
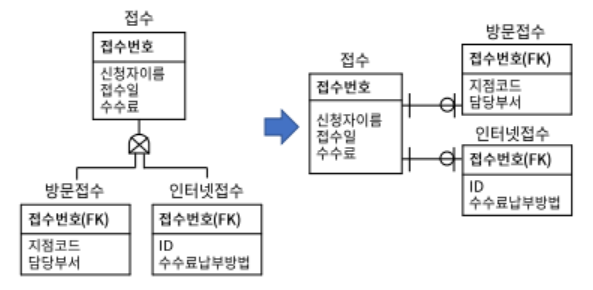
2. 물리 E-R 다이어그램
- 논리데이터 모델 물리 데이터 모델 변환
- 단위 엔티티 -> 테이블
- 속성 -> 칼럼
- UID -> 기본키
- 관계 -> 외래키
- 관리 목적의 테이블/칼럼 추가
- 칼럼 유형과 길이 정의
- 데이터 표준 적용
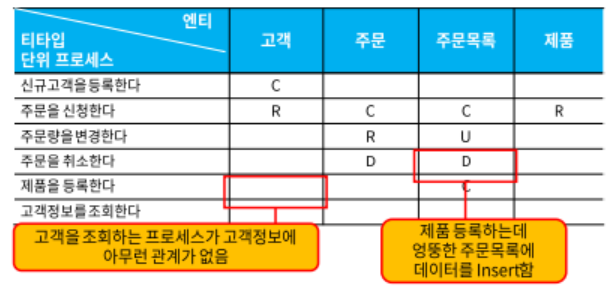
3. CRUD 분석
- CRUD 매트릭스 분석 개념
- 데이터 프로세스를 행으로 하고 엔티티 목록을 열로 하여 CRUD Matrix를 작성한 후 CRUD Matrix에서 사용되지 않는 프로세스와 엔티티 여부 확인하는 분석 기법
- 점검사항
- 모든 엔티티 타입에 CRUD가 한 번 이상 표기되었는가?
- 모든 엔티티 타입에 C가 한 번 이상 존재하는가?
- 모든 엔티티 타입에 R이 한 번 이상 존재하는가?
- 모든 단위 프로세스가 하나 이상의 엔티티 타입에 표기가 되는가?
4. SQL 성능 튜닝
- SQL 성능 튜닝의 정의
- 튜닝 대상이 되는 SQL을 이해하고 정보를 분석하여 성능을 개선하는
활동
- 튜닝 대상이 되는 SQL을 이해하고 정보를 분석하여 성능을 개선하는
- SQL 성능 튜닝의 순서
- 문제 있는 SQL 식별
- 옵티마이저 통계 확인
- 실행 계획 검토
- SQL문 재구성
- 인덱스 재구성
- 실행 계획 유지 관리