





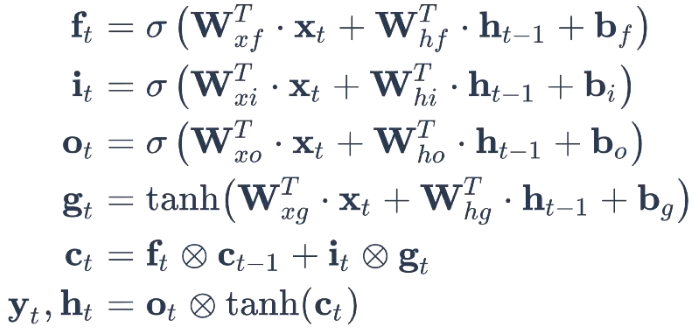
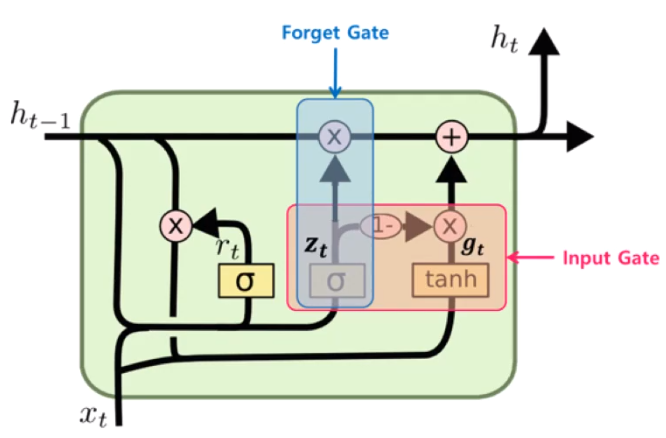
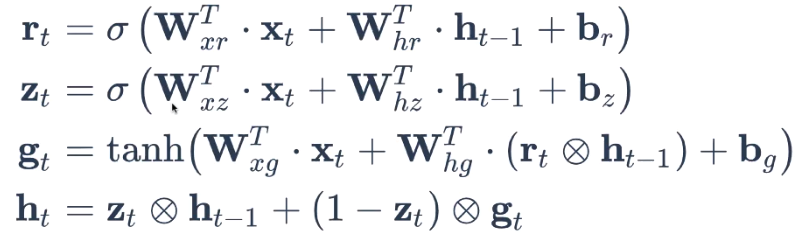

챗봇만들기(3)
데이터 분석(2)
질문, 답변 각각에 대한 문장 길이 분포 분석
- 형태소를 기준으로 길이 분석
1 | query_sentences = list(data['Q']) |
- 질문 열과 답변 열을 각각 리스트로 정의
- KoNLpy의 Okt 형태소 분석기를 이용해 토크나이저 구분
- 구분된 데이터의 길이를 하나의 변수로 만듬
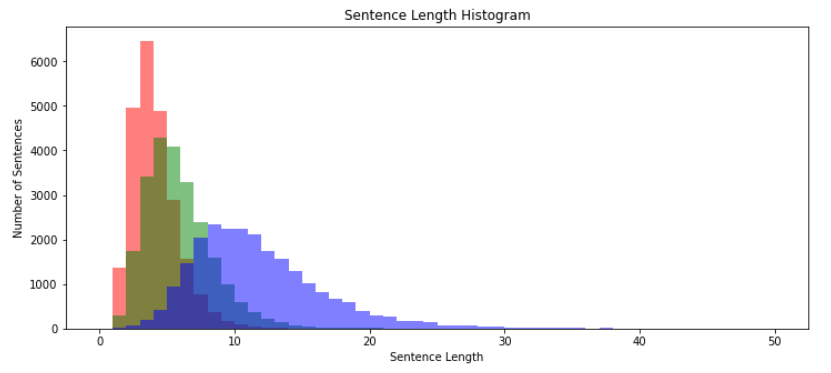
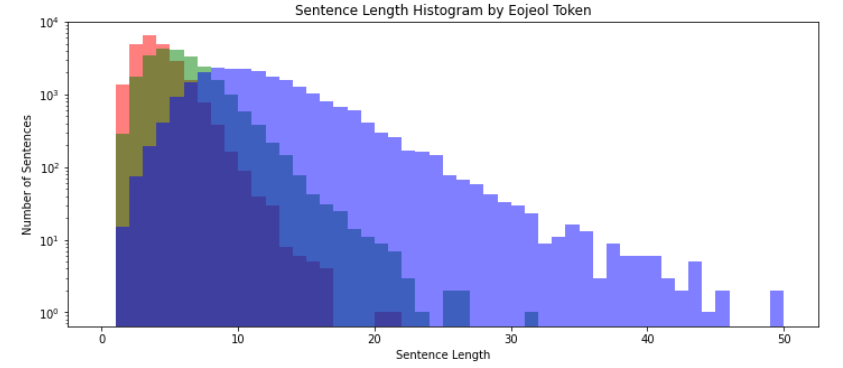
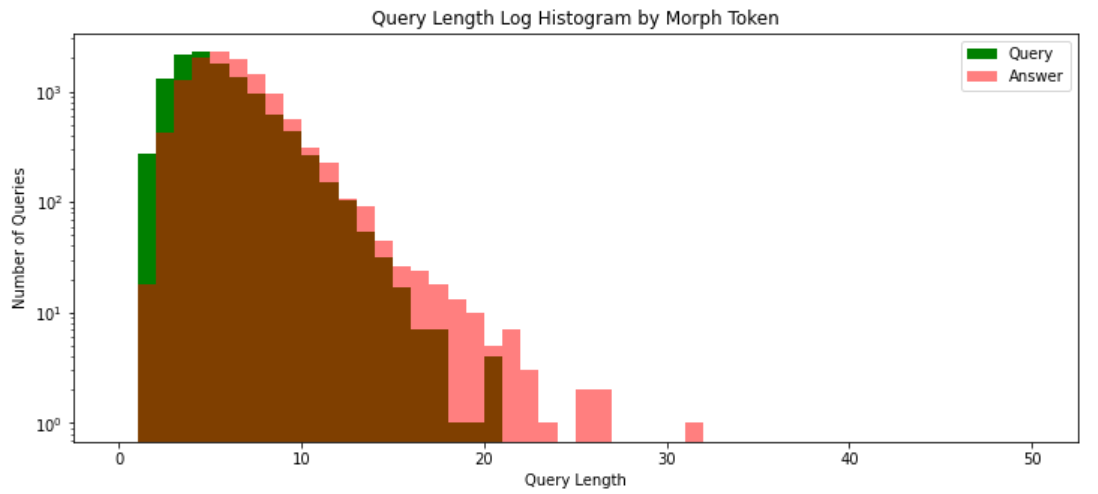
질문 응답 데이터 길이에 대한 히스토그램
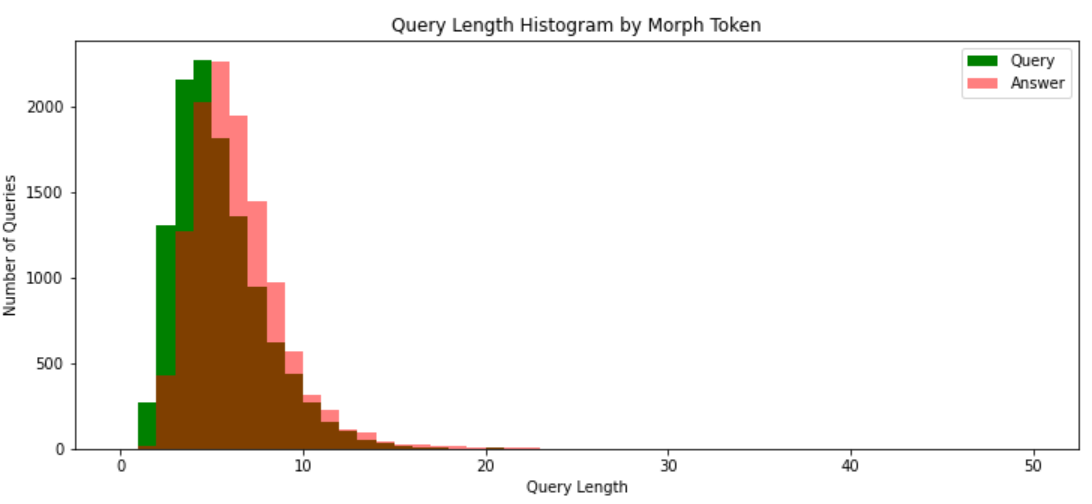
- 질문 문장 길이가 응답 문장 길이보다 상대적으로 짧음
- y 값의 크기를 조정
1 | plt.figure(figsize=(12, 5)) |
-
plt.yscale(‘log’, nonposy=‘clip’) 추가
-
답변 데이터가 질문 데이터 보다 이상치 값이 많음
-
상대적으로 질문의 경우 평균 주변에 잘 분포
통곗값 확인하기
1 | print('형태소 최대길이: {}'.format(np.max(query_sent_len_by_morph))) |
형태소 최대길이: 20
형태소 최소길이: 1
형태소 평균길이: 4.95
형태소 길이 표준편차: 2.48
형태소 중간길이: 4.0
형태소 1/4 퍼센타일 길이: 3.0
형태소 3/4 퍼센타일 길이: 6.0
1 | print('형태소 최대길이: {}'.format(np.max(answer_sent_len_by_morph))) |
형태소 최대길이: 31
형태소 최소길이: 1
형태소 평균길이: 5.87
형태소 길이 표준편차: 2.55
형태소 중간길이: 5.0
형태소 1/4 퍼센타일 길이: 4.0
형태소 3/4 퍼센타일 길이: 7.0
- 최댓값의 경우 답변 데이터가 더 큼
- 평균의 경우 질문 데이터가 좀 더 작음
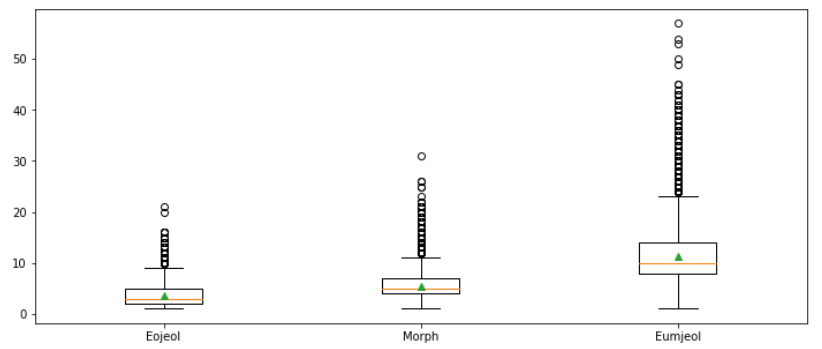
박스플롯그리기
1 | plt.figure(figsize=(12, 5)) |
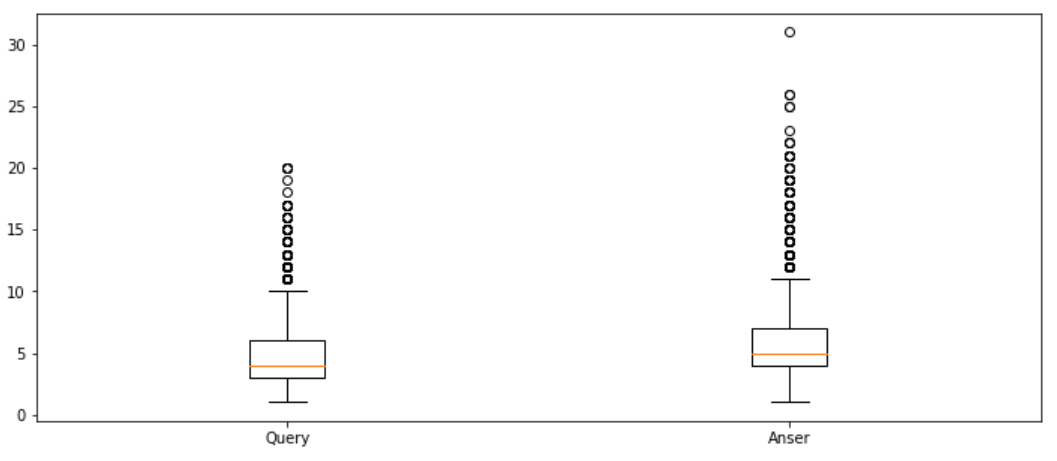
- 통계값과는 다소 다름
- 통계값 : 답변 데이터에 대한 평균 길이가 질문 데이터보다 길었음
- 박스플롯 : 질문 데이터가 더 큼
-> 답변 데이터의 경우 길이가 긴 이상치 데이터가 많아서 평균값이 더욱 크게 측정됨 - 길이 값을 통해 모델에 적용될 문장의 최대 길이를 결정한다
데이터 어휘 빈도 분석
- 형태소 단위로 토크나이징한 데이터를 사용해 자주 사용하는 단어 파악
- ‘이’, ‘가’ 등의 조사보다는 의미상 중요한 명사, 형용사, 동사를 따로 모은 후 파악
- KoNPy의 품사분류 POS-tagging 모듈
1 | okt.pos('나는학생입니다') |
[(‘나’, ‘Noun’), (‘는’, ‘Josa’), (‘학생’, ‘Noun’), (‘입니다’, ‘Adjective’)]
[(‘지금’, ‘Noun’), (‘은’, ‘Josa’), (‘5월’, ‘Number’), (‘여름입니다’, ‘Foreign’)]
- 문장에서 명사, 형용사, 동사를 제외한 단어를 모두 제거한 문자열 만들기
1 | query_NVA_token_sentences = list() |
워드클라우드 활용해 어휘 빈도 분석
- NanumGothic.ttf 한글 폰트 설정
- 질문
1 | from wordcloud import WordCloud |

- 답변
1 | query_wordcloud = WordCloud(font_path= DATA_IN_PATH + 'NanumGothic.ttf').generate(answer_NVA_token_sentences) |
