
2.2 어떤 단어가 많이 쓰였는가
2.2.1 백오브워즈 가정
수학에서 백이란 중복 원소를 허용한 집합 multiset을 뜻한다. 원소의 순서는 고려하지 않는다. 어쩌면 중복 집합과 같다.
자연어 처리 분야에서는 백오브워즈 bag of words란
- 단어의 등장 순서에 관계없이 문서 내 단어의 등장 빈도를 임베딩으로 쓰는 기법
- 문장을 단어들로 나누고 이들을 중복집합에 넣어 임베딩으로 활용하는 것
- 저자가 생각한 주제가 문서에서의 단어 사용에 녹아 있을 것
- 주제가 비슷한 문서라면 단어 빈도 또는 단어 등장 역시 비슷하 것
- 빈도를 그대로 백오브워즈로 쓴다면 많이 쓰인 단어가 주제와 더 강한 관련을 맺고 있을 것

위 처럼 문장을 단어로 쪼개고 임의의 주머니에 넣고 뽑았을 때 등장하면 1 아니면 0을 반영한 것이다.
백오브워즈 임베딩은 단순하지만 정보 검색 ** Information Retrieval분야에서 많이 쓰인다.
사용자의 질의 ** query에 가장 적절한 문서를 보여줄 때 질의를 백오브워즈 임베딩으로 변환하고 질의와 검색 대상 문서 임베딩 간 코사인 유사도를 구해 유사도가 가장 높은 문서를 사용자에게 노출한다.
2.2.2 TF-IDF
단어 빈도 또는 등장 여부를 그대로 임베딩으로 쓰는 것에는 단점이 있다. 해당 단어가 많이 나왔다고 하더라도 문서의 주제를 가늠하기 어렵다. 이유는 다음과 같다. ‘을/를’, ‘이/가’ 같은 조사들이 한국어 문서에 등장한다. 이 것으로 문서의 주제를 추측하기 어렵다.
이런 단점을 보완하기 위해서 Term Frequency-Inverse Document Frequency이다.
단어-문서 행렬에 가중치를 계산해 행렬 원소를 바꾼다. 이 또한 단어 등장 순서는 고려하지 않는다.
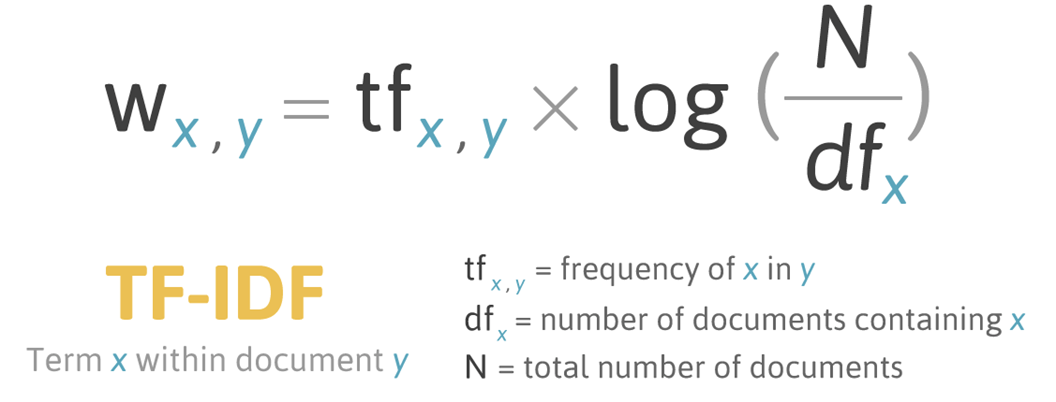
위 수식을 자세히 알아보자
- TF는 어떤 단어가 특정 문서에 얼마나 많이 쓰였는지 빈도를 나타낸다.
- A라는 단어가 문서1에 10번, 문서2에 5번 쓰였다면 문서1 - 단어A의 TF는 10, 문서2 - 단어A의 TF는 5
- DF란 특정 단어가 나타난 문서의 수를 뜻한다.
- 문서1과 문서2에만 A가 등장했으므로 DF는 2D
- DF가 클수록 다수 문서에 쓰이는 범용적 단어이다
- IDF는 전체 문서 수를 해당 단어의 DF로 나눈 뒤 로그를 취한 값이다.
- 그 값이 클수록 특이한 단어이다.
- 주제 예측 능력과 직결된다
결국 TF-IDF는 어떤 단어의 주제 예측 능력이 강할 수록 가중치가 커지고 그 반대의 경우 작아진다
어떤 단어의 TF가 높으면 TF-IDF 값 역시 커진다
단어 사용 빈도는 저자가 상정한 주제와 관련을 맺고 있을 거라는 가정에 기초한 것이다
2.2.3 Deep Averaging Network
Deep Averaging Network는 백오브워즈 가정의 뉴럴 네트워크 버전이다.
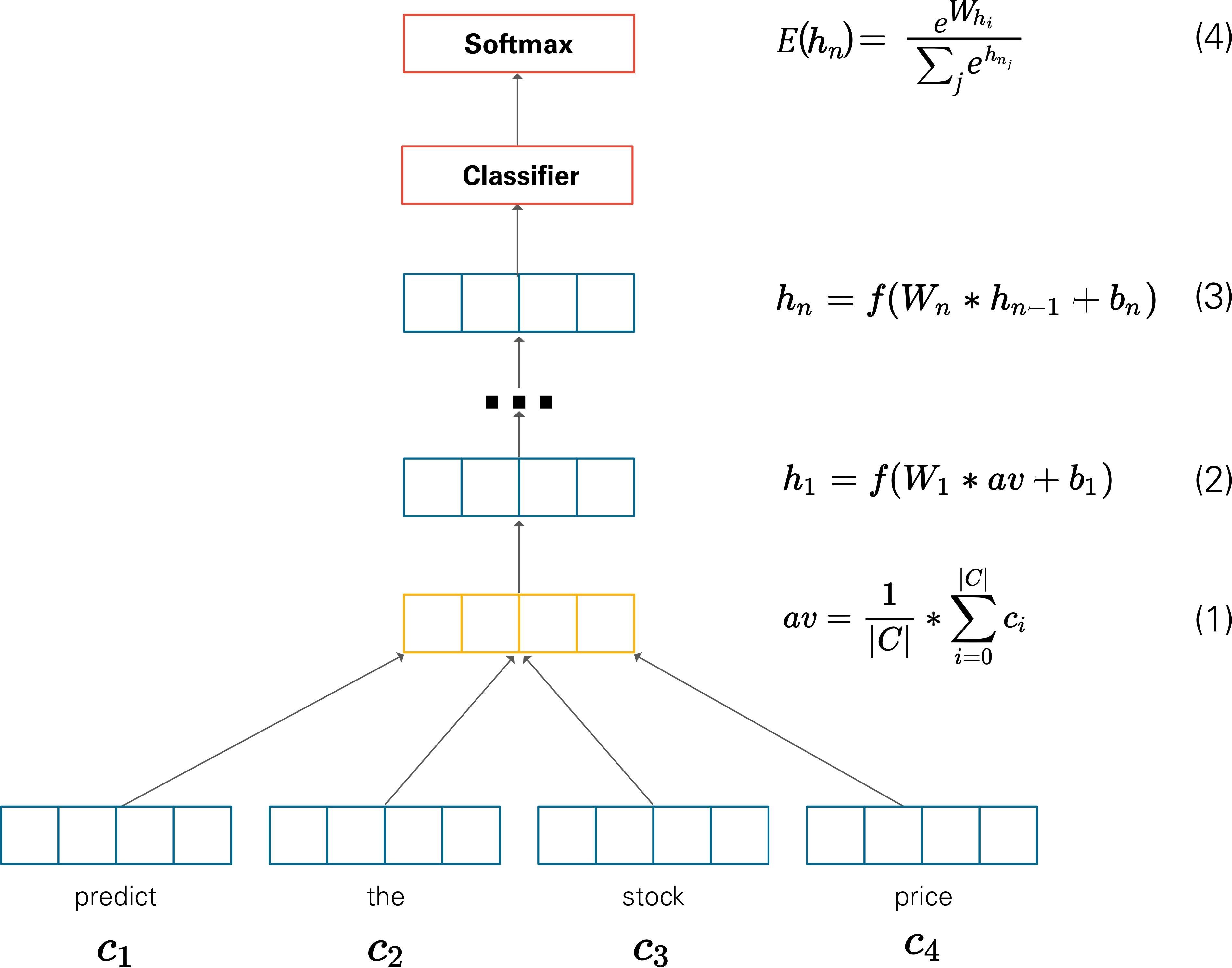
예를 들어 애비는 종이었다 라는 문장이 있다면
{애비, 종, 이, 었, 다}에 속한 단어의 임베딩을 평균을 취해 만든다. 문장 내에 어떤 단어가 쓰였는지, 쓰였다면 얼마나 많이 쓰였는지 그 빈도만을 고려한다. 문장 임베딩을 입력받아 해당 문서가 어떤 범주인지 분류 classifiation 한다.