

챗봇만들기(2)
데이터 분석(1)
- 데이터 분석
- 데이터 전처리와 모델 생성
데이터 불러오기
1 | import pandas as pd |
| Q | A | label |
|---|---|---|
| 0 | 12시 땡! | 하루가 또 가네요. |
| 1 | 1지망 학교 떨어졌어 | 위로해 드립니다. |
| 2 | 3박4일 놀러가고 싶다 | 여행은 언제나 좋죠. |
| 3 | 3박4일 정도 놀러가고 싶다 | 여행은 언제나 좋죠. |
| 4 | PPL 심하네 | 눈살이 찌푸려지죠. |
문장 전체에 대한 분석
- 데이터 길이를 분석
- 질문과 답변 모두 길이에 대해 분석하기 위해 두 데이터를 하나의 리스트로 만들기
1 | sentences = list(data['Q']) + list(data['A']) |
- 세 가지 기준으로 분석을 진행
- 문자 단위의 길이 분석 (음절)
- 문자 하나하나를 생각하자
- 단어 단위의 길이 분석 (어절)
- 띄어쓰기 단위로 생각하자
- 형태소 단위의 길이 분석
- 어절과 음절 사이로 생각하자
- 최소 단위를 의미
ex) 나는 학생이다.
- 음절 : “나”, “는”, “학”, “생”, “이”, “다”
- 어절 : “나는”, “학생이다”
- 형태소 : “나”, “는”, 학생", “이다”
- 문자 단위의 길이 분석 (음절)
토크나이징
- KoNLPy 사용
1 | tokenized_sentences = [s.split() for s in sentences] |
- 띄어쓰기 기준으로 문장 분류 -> 어절의 길이 측정
- 위 값을 붙이기 -> 음절의 길이
- KoNLPy에 Okt 형태소 분석기 사용해서 나눈 후 길이 측정
그래프그리기
- matplot사용
1 | import matplotlib.pyplot as plt |
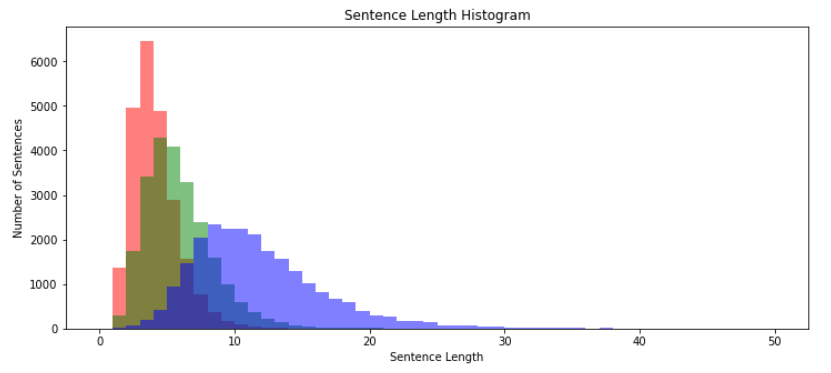
- 빨간색 : 어절 단위 히스토그램
- 초록색 : 형태소
- 파란색 : 음절
그래프 해석
- 어절이 가장 낮은 길이 그다음 형태소, 가장 긴 길이는 음절
- 히스토그램을 통해 각 길이가 어느 쪽으로 치우쳐 있는지 혹은 각 데이터에 이상치는 없는지 확인하자
- 이 그래프는 직관적으로는 어렵다
- y값 분포가 다르기 때문
- 수정을 해보자
1 | plt.figure(figsize=(12, 5)) |
- plt.yscale(‘log’) 사용
- 각 그래프가 커지는 y값의 스케일을 조정함으로써 차이가 큰 데이터에서도 함께 비교 가능
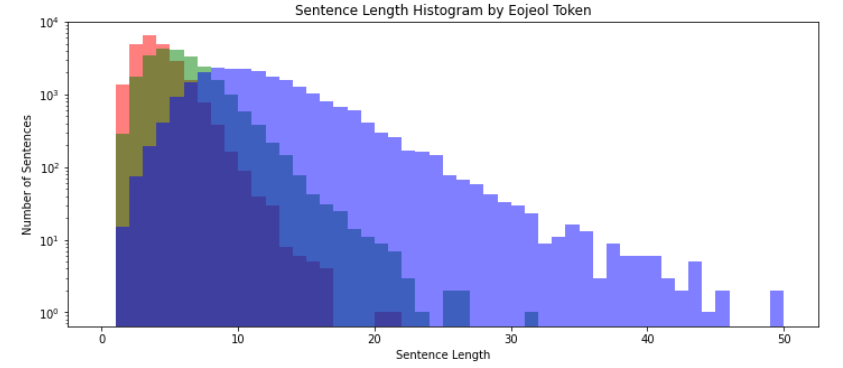
- 각 그래프가 커지는 y값의 스케일을 조정함으로써 차이가 큰 데이터에서도 함께 비교 가능
- 꼬리부분의 분포가 보임
- 어절의 경우 길이가 20인 경우가 이상치 데이터로 존재
- 형태소는 30, 음절은 45정도 길이에 이상치가 존재
- 이러한 길이 분포에 대한 분석 내용을 바탕으로 입력 문장의 길이를 어떻게 설정할지 정의하면 됨
통계값출력
- 정확한 수치 확인을 위해 각 기준별 길이에 대한 여러가지 통곗값 비교
어절
1 | import numpy as np |
어절 최대길이: 21
어절 최소길이: 1
어절 평균길이: 3.64
어절 길이 표준편차: 1.74
어절 중간길이: 3.0
제 1 사분위 길이: 2.0
제 3 사분위 길이: 5.0
형태소
1 | print('형태소 최대길이: {}'.format(np.max(sent_len_by_morph))) |
형태소 최대길이: 31
형태소 최소길이: 1
형태소 평균길이: 5.41
형태소 길이 표준편차: 2.56
형태소 중간길이: 5.0
형태소 1/4 퍼센타일 길이: 4.0
형태소 3/4 퍼센타일 길이: 7.0
음절
1 | print('음절 최대길이: {}'.format(np.max(sent_len_by_eumjeol))) |
음절 최대길이: 57
음절 최소길이: 1
음절 평균길이: 11.31
음절 길이 표준편차: 4.98
음절 중간길이: 10.0
음절 1/4 퍼센타일 길이: 8.0
음절 3/4 퍼센타일 길이: 14.0
- 전체 문자 수는 11개 정도의 평균값을 갖고 있음
- 띄어쓰기로 구분한 어절의 경우 3~4 정도의 평균
- 형태소로 분석시 6~7 정도의 평균
박스플롯그리기
1 | plt.figure(figsize=(12, 5)) |
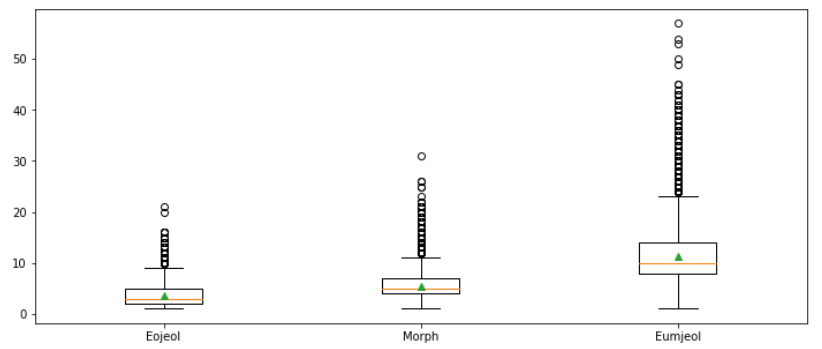
- 꼬리가 긴 형태로 분포됨
- 5~15의 길이를 중심으로 분포를 이루고 있음
- 음절은 어절과 형태소에 비해 분포가 큼