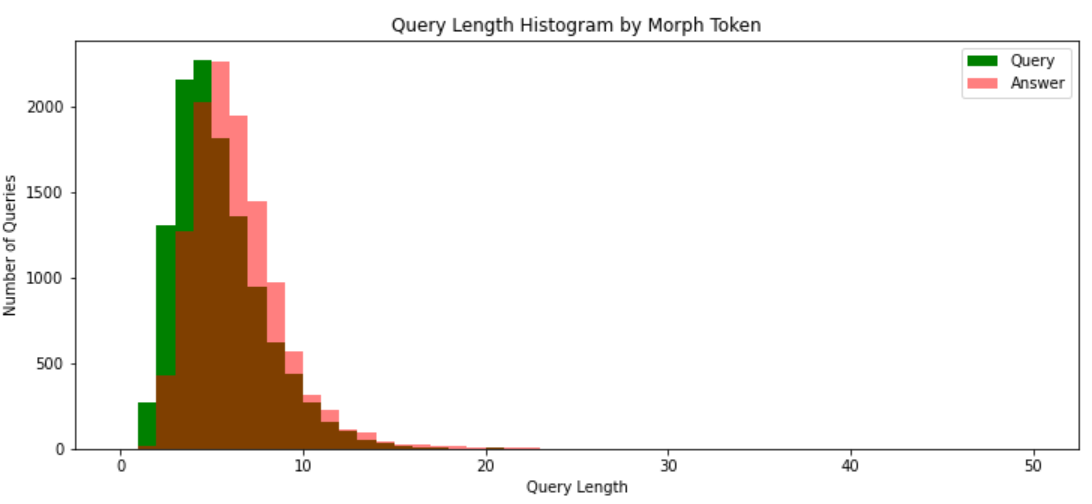
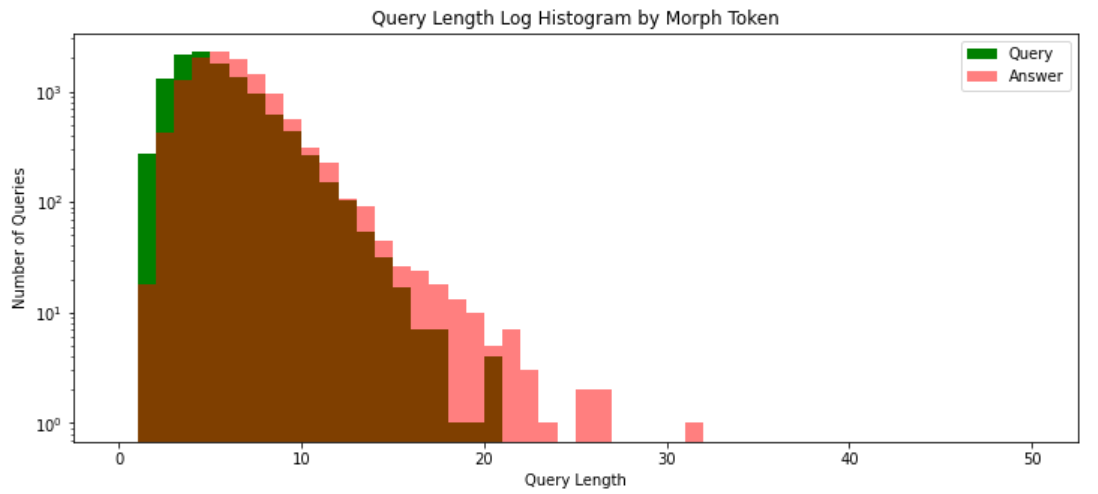
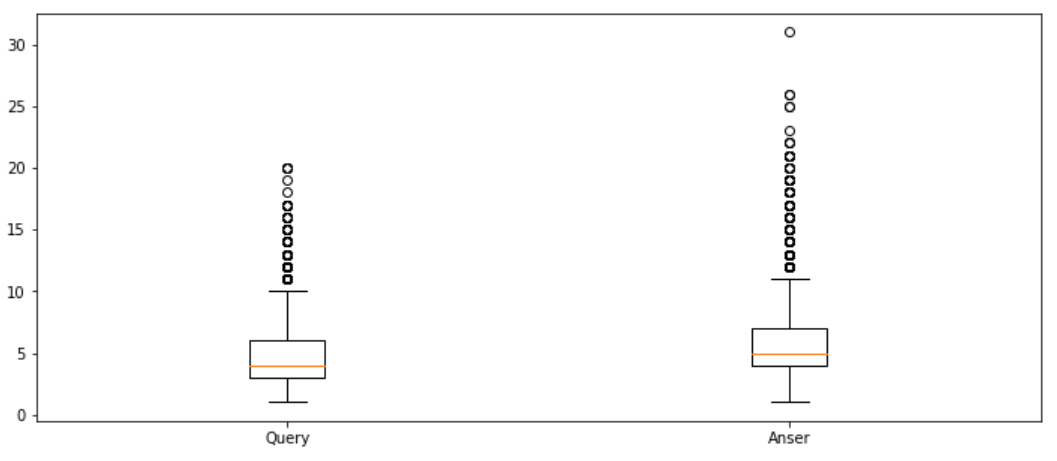
query_morph_tokenized_sentences = [okt.morphs(s.replace(' ', '')) for s in query_sentences] query_sent_len_by_morph = [len(t) for t in query_morph_tokenized_sentences]
answer_morph_tokenized_sentences = [okt.morphs(s.replace(' ', '')) for s in answer_sentences] answer_sent_len_by_morph = [len(t) for t in answer_morph_tokenized_sentences]
for s in query_sentences: for token, tag in okt.pos(s.replace(' ', '')): if tag == 'Noun'or tag == 'Verb'or tag == 'Adjective': query_NVA_token_sentences.append(token)
for s in answer_sentences: temp_token_bucket = list() for token, tag in okt.pos(s.replace(' ', '')): if tag == 'Noun'or tag == 'Verb'or tag == 'Adjective': answer_NVA_token_sentences.append(token) query_NVA_token_sentences = ' '.join(query_NVA_token_sentences) answer_NVA_token_sentences = ' '.join(answer_NVA_token_sentences)
워드클라우드 활용해 어휘 빈도 분석
NanumGothic.ttf 한글 폰트 설정
질문
1 2 3 4 5 6
from wordcloud import WordCloud query_wordcloud = WordCloud(font_path= DATA_IN_PATH + 'NanumGothic.ttf').generate(query_NVA_token_sentences)