




Neural Machine Translation
- 기계번역
- Sequence to Sequence
- Encoder
- Decoder
- From English to Korean
- From German to Korean
- Speech to Text
- Text to Speech
Process
-
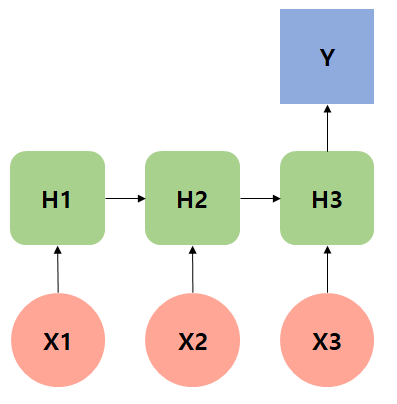
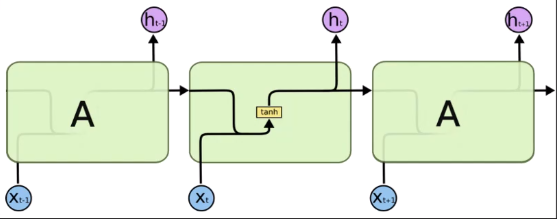
Sequence to Sequence
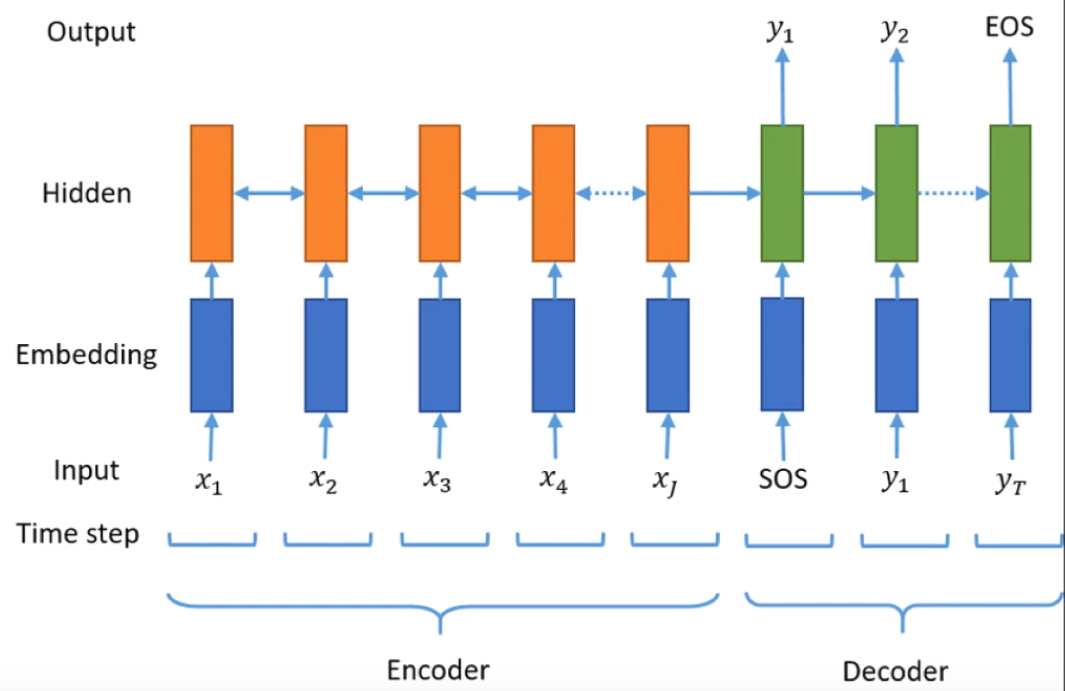
인코더와 디코더의 구조. 인코더는 이용하고자 하는 대상 즉 소스. 한글에서 영어로 번역하는 태스크 일때, 인코더는 한글데이터 디코더는 영어데이터. 한글문장을 바꾸어보자.
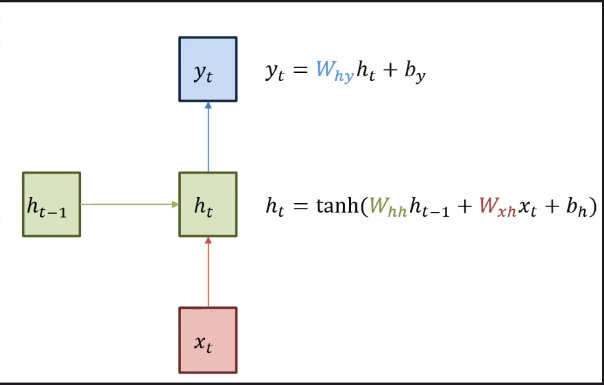
한글 형태소 토크나이저를 이용해 나누기. 그게 x1, x2, x3 … xj가 된다. 그다음 corpus(단어사전)를 만든다. 해당단어를 인덱스로 바꾸어준다. x1은 넘버링이 들어가고 넘버링을 원-핫 벡터로 치환해서 들어간다. 파란색이 임베딩 벡터를 가져옴 RNN input으로 들어감 그전에 weight 매트릭스를 곱하고 바이어스가 더해진 값이 들어간다.
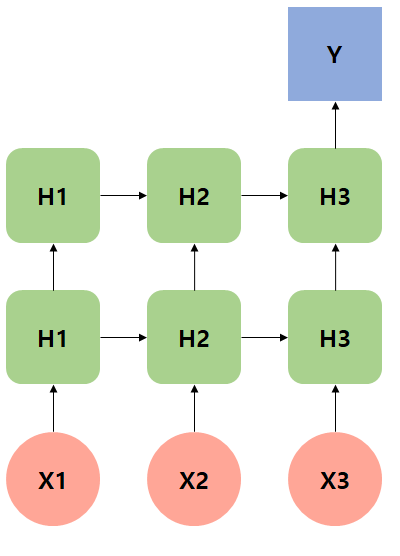
Encoder의 output 값이 Decoder의 input 값이 된다.
SOS는 Start of Sentence
EOS는 End of Sentence
y1는 영어딕셔너리에서 뽑힌 값이다.
y1은 softmax를 통해서 가장 큰 값을 뽑아준다. -
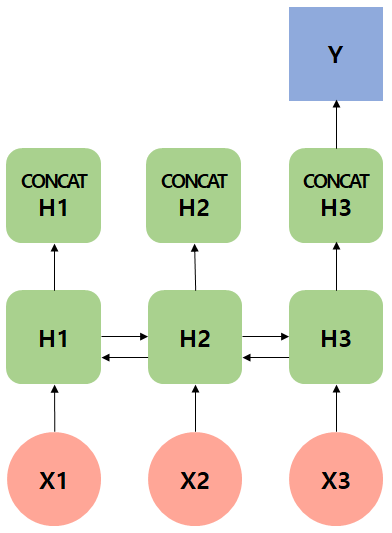
with Attention
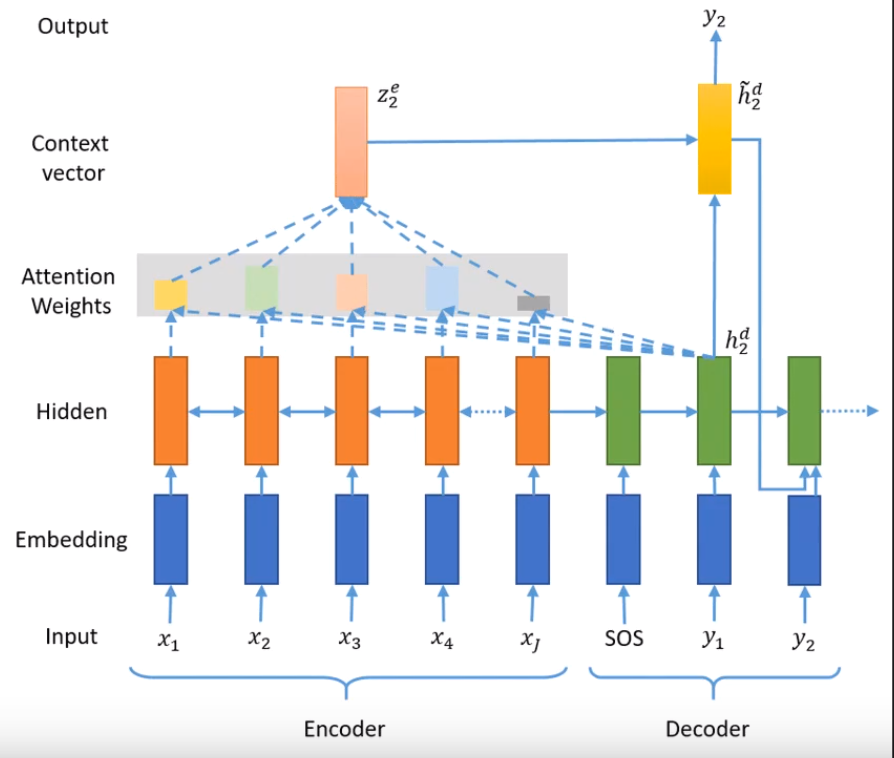
hidden state만으로 y2가 부족하다고 판단할 수 있다. Encoder의 hidden state 값과 y2의 hidden state 값을 전부 내적한다. 어떤 스칼라의 값을 Attention Weight를 계산한다. 전부 0~1사이의 값으로 각각 바뀐다. 총 합이 1이 된다. 그리고 context vector로 만들어준다. 각 hidden state 별로 얼마나 가중있게 보아야하는지 척도를 알 수 있다.
Transformer
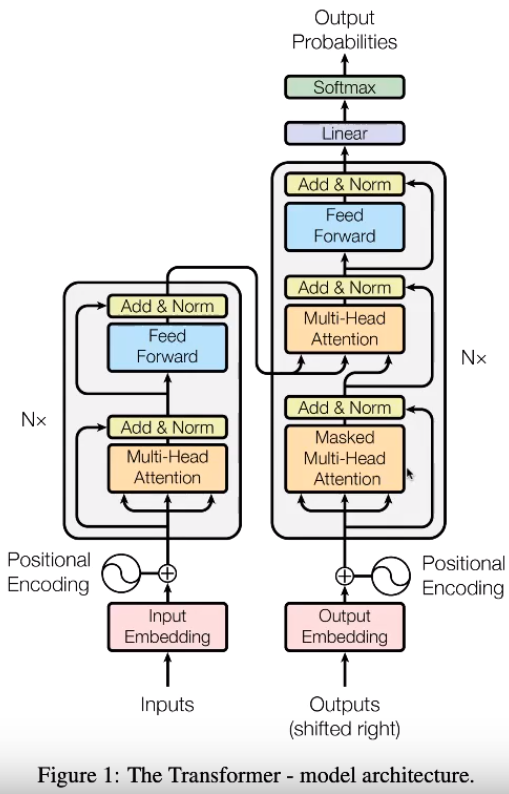
- Attention is all you need(Ashishi Vaswani et al, 2017)
- 기존에는 RNN구조를 이용해서 Seq2Seq을 풀어냈다면 이 논문에서는 Attention 매커니즘만 이용하겠다. 훨씬 더 기계번역이 좋다.
- Using Only Attention Mechanism for Seq2Seq
- Basic concept of BERT