

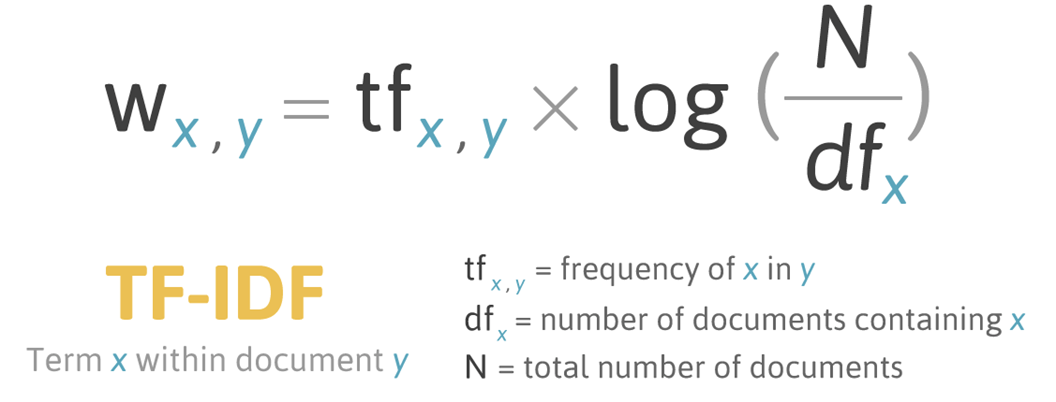







2.3 단어가 어떤 순서로 쓰였는가
2.3.1 통계 기반 언어 모델
언어 모델 ** language model**이란 단어 시퀀스에 확률을 부여하는 모델이다.
단어의 등장 순서를 무시하는 백오브워즈와 달리 언어 모델은 시퀀스 정보를 명시적으로 학습한다.
단어가 n개 주어진 상황이라면 언어 모델은 n개 단어가 동시에 나타날 확률, 즉 P라는 것을 반환한다. 통계 기반의 언어 모델은 말뭉치에서 해당 단어 시퀀스가 얼마나 자주 등장하는지 빈도를 세어 학습한다. 이렇게 되면 주어진 단어 시퀀스 다음 단어는 무엇이 오는게 자연스러운지 알 수 있다.
n-gram이란 n개 단어를 뜻하는 용어이다. 난폭,운전 눈_뜨다 등은 2-gram 또는 bigram이라는 말을 쓴다. 누명, 을, 쓰다 는 3-gram 혹은 trigram이라고 쓴다. 경우에 따라서 n-gram은 n-gram에 기반한 언어 모델을 의미하기도 한다. 말뭉치 내 단어들을 n개씩 묶어서 그 빈도를 학습했다는 뜻이다.
예컨데 내, 내_마음 말뭉치는 빈도가 많지만 내_마음_속에_영원히_기억될_최고의_명작이다 라는 말뭉치가 한 번도 없을 수 있다. 이럴 때에는 말뭉치로 학습한 언어 모델은 해당 표현이 나타날 확률을 0으로 부여하게 된다.
문법적으로나 의미적으로 결함이 없는 훌륭한 한국어 문장임에도 해당 표현을 말이 되지 않는 문장으로 취급할 수 있다는 것이다.
내_마음_속에_영원히_기억될_최고의 라는 표현 다음에 명작이다라는 단어가 나타날 확률은 조건부확률 ** conditional probability**의 정의를 활용해 최대우도추정법 으로 유도한다.
그러나 우변의 분자가 0이라서 전체 값은 0이된다.
앞에서 배운 n-gram을 사용해보자. 직전 n-1개 단어의 등장 확률로 전체 단어 시퀀스 등장 확률을 근사하는 것이다. 이말을 다시 해석하면 한 상태** state**의 확률은 그 직전 상태에만 영향을 받는 것이다. 마코프 가정 Markov assumption에 기반한 것이다.
처럼 전 상황에 대해서만 영향을 주는 것이다. 다시말해 명작이다 라는 직전의 1개 단어만 보고 전체 단어 시퀀스 등장 확률을 근사한 것이다.
좀 더 늘려서 끝까지 계산하게 되면 다음과 같다.
일반화를 시킨다면 다음과 같다. 바이그램모델에서는 1개만 참고하지만 일반화를 시키면 전체 단어 시퀀스 등장 확률 계산시 직전 n-1개 단어의 히스토리를 본다
그러나 데이터에 한 번도 등장하지 않는 n-gram이 존재할 때 예측 문제가 발생할 수 있다. 처음 보는 단어를 본다면 그 확률은 0으로 보기 때문이다.
이를 위해서 백오프** back-off**, 스무딩 ** smoothing**등의 방식이 제안된다.
백오프란 n-gram등장 빈도를 n보다 작은 범위의 단어 시퀀스 빈도로 근사하는 방식인데, n을 크게 하면 할 수록 등장하지 않은 케이스가 많아질 가능성이 높기 때문이다.
내_마음_속에_영원히_기억될_최고의_명작이다는 7-gram에서는 0이지만 N을 4로 내린다면 달라진다.
스무딩이란 등장 빈도 표에 모두 K만큼 더하는 것이다. 높은 빈도를 가진 문자열 등장 확률을 일부 깎고 학습 데이터에 전혀 등장하지 않은 케이스들에는 일부 확률을 부여하게 된다.
2.3.2 뉴럴 네트워크 기반 언어 모델
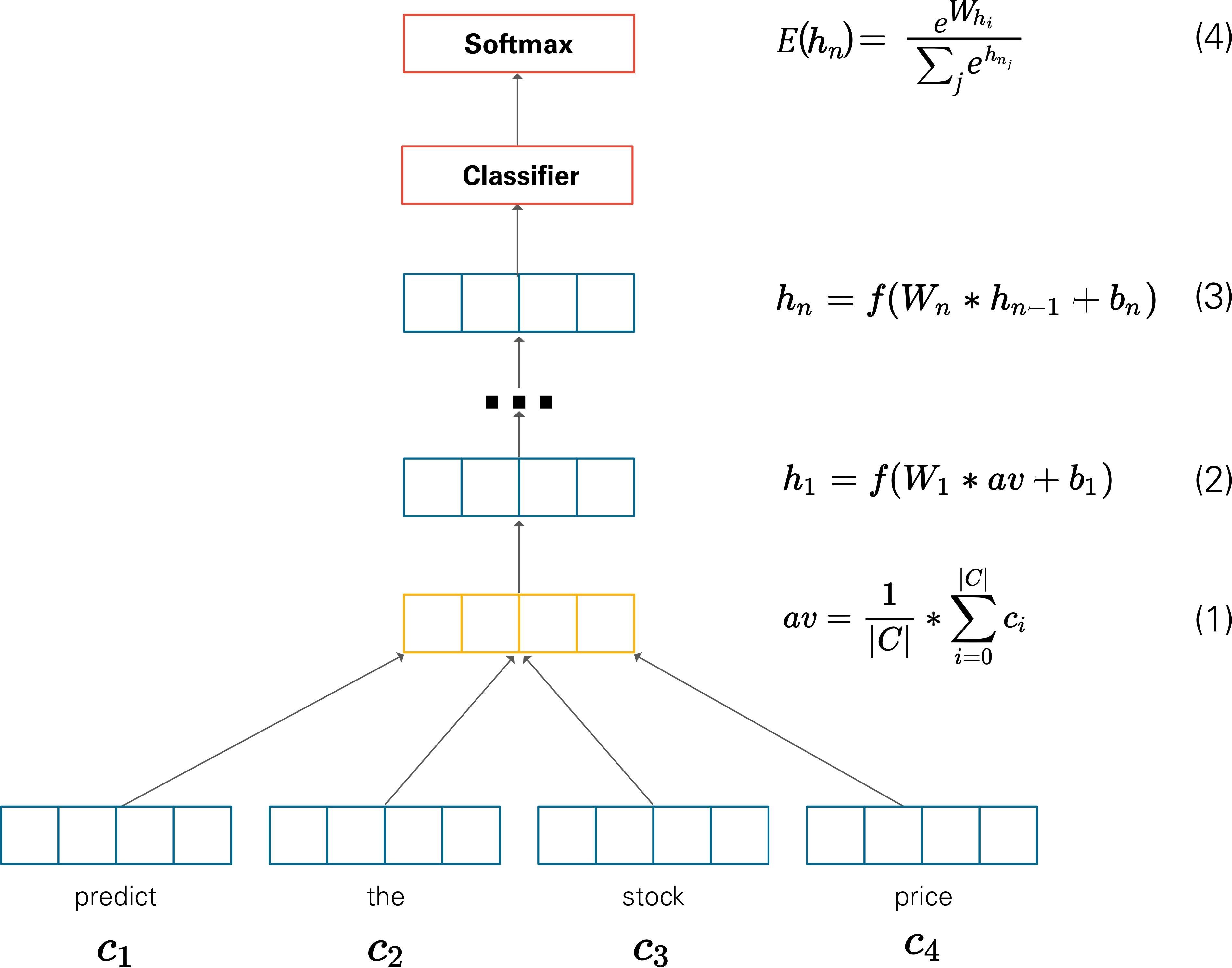
뉴럴 네트워크는 입력과 출력 사이의 관계를 유연하게 포착해낼 수 있고, 그 자체로 확률 모델로 기능이 가능하기 때문에 뉴럴 네트워크로 사용한다.
1 | 발 없는 말이 -> [언어모델] -> 천리 |
뉴럴 네트워크 기반 언어 모델은 위 그림처럼 단어 시퀀스를 가지고 다음 단어를 맞추는 과정에서 학습된다. 학습이 완료되면 이들 모델의 중간 혹은 말단 계산 결과물을 단어나 문장의 임베딩으로 활용한다. 대표적인 모델은 다음과 같다.
- ELMo
- GPT
마스크 언어 모델 ** masked language model**은 언어 모델 기반 기법과 큰 틀에서 유사하지만 디테일에서 차이가 잇다. 문장 중간에 '마스크’를 씌워 놓고 해당 위치에 어떤 단어가 올지 예측하는 과정을 학습한다.
대게 언어 모델 기반 기법은 단어를 순차적으로 입력받아 다음 단어를 맞춰야하기 때문에 태생적으로 일방향 ** uni-directional이다. 하지만 마스크 언어 모델 기반 기법은 문장 전체를 보고 중간을 예측하기 때문에 양방향 ** bi-directional학습이 가능하다. 대표적인 모델은 다음과 같다.
- BERT