

데이터입출력구현
- 논리데이터저장소 설계를 바탕으로 응용소프트웨어가 사용하는 데이터저장소의 특성을 반영한 물리 데이터 저장소 설계 수행
- 논리데이터저장소 설계를 바탕으로 목표 시스템의 데이터 특성을 반영하여 최적화된 물리 데이터저장소를 설계
- 실제 데이터가 저장될 물리적 공간을 구성
데이터베이스 스키마 Schema의 개념
- 데이터베이스에서 자료의 구조, 자료의 표현방법, 자료 간의 관계를 형식 언어로 정의한 구조
데이터베이스 스키마 종류
- 외부 스키마
- 프로그래머나 사용자의 입장에서 데이터베이스의 모습으로 조직의 일부분을 정의한 것
- 개념 스키마
- 모든 응용 시스템과 사용자들이 필요로 하는 데이터를 통합한 조직 전체의 데이터베이스 구조를 논리적으로 정의 한 것
- 내부 스키마
- 전체 데이터베이스의 물리적 저장 형태를 기술
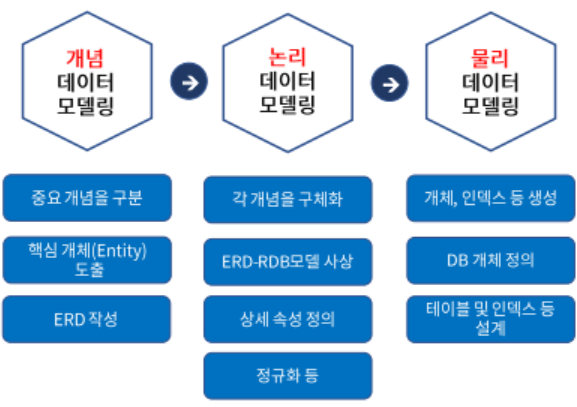
논리 데이터 모델 -> 물리 데이터 모델 변환 순서
- 단위 엔티티를 테이블로 변환
- 논리 모델에서 정의된 엔티티는 물리 모델에서 테이블로 변환
- 엔티티는 한글명, 테이블은 영문명 사용하고 명칭을 동일하게
- 속성을 칼럼으로 변환
- SQL 예약어 사용은 피하기
- 가독성을 위해 명칭은 가능한 짧게
- 칼럼명에 복합 단어 사용할 경우 미리 정의된 표준에 의해 명명
- UID를 기본키로 변환
- 엔티티의 UID는 기본키로 선언
- Not null, Unique 등의 제약 조건을 추가적으로 정의
- 관계를 외래키로 변환
- 1:n 관계에서 1 영역에 있는 기본키를 n영역의 외래키로 선언
- 외래키 명은 1 영역의 기본키 이름을 사용하나 다른 의미를 가질 경우 변경하여 명명
- 순환 관계에서 자신의 기본키는 외래키로 정의
- 칼럼 유형과 길이 정의
- 정의된 각 칼럼에 대해, 적용 DBMS에서 제공하는 데이터 유형 중 적절한 유형 정의
- 해당 데이터의 최대 길이를 파악하여 길이 설정
- 데이터 처리 범위와 빈도수를 분석하여 반정규화 고려
- 중복 테이블 추가
- 테이블 조합
- 테이블 분할
- 수식 분할
- 수평 분할
- 테이블 제거
- 더 이상 엑세스 되지 않는 테이블
- 칼럼의 중복화