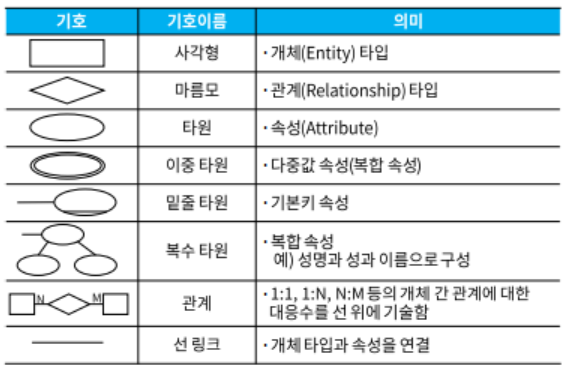
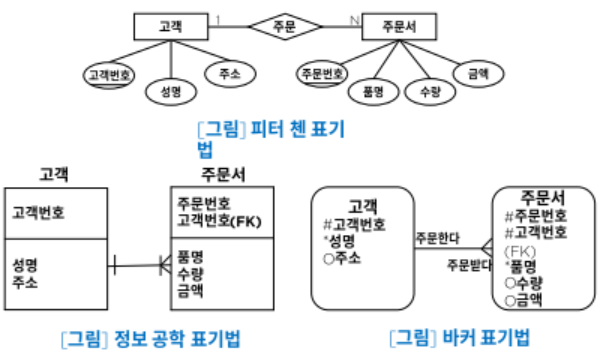
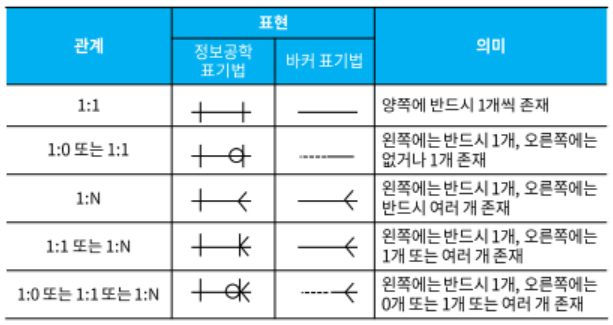
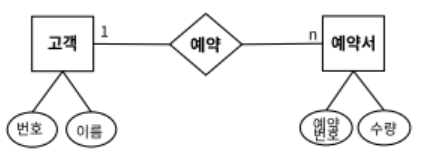
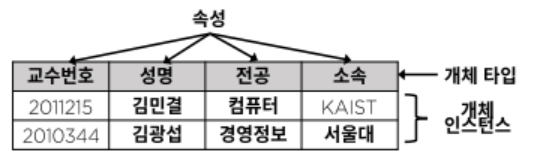
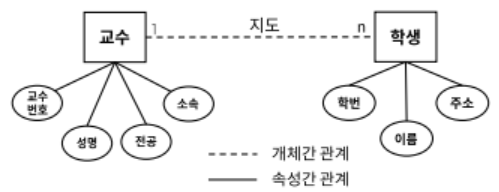
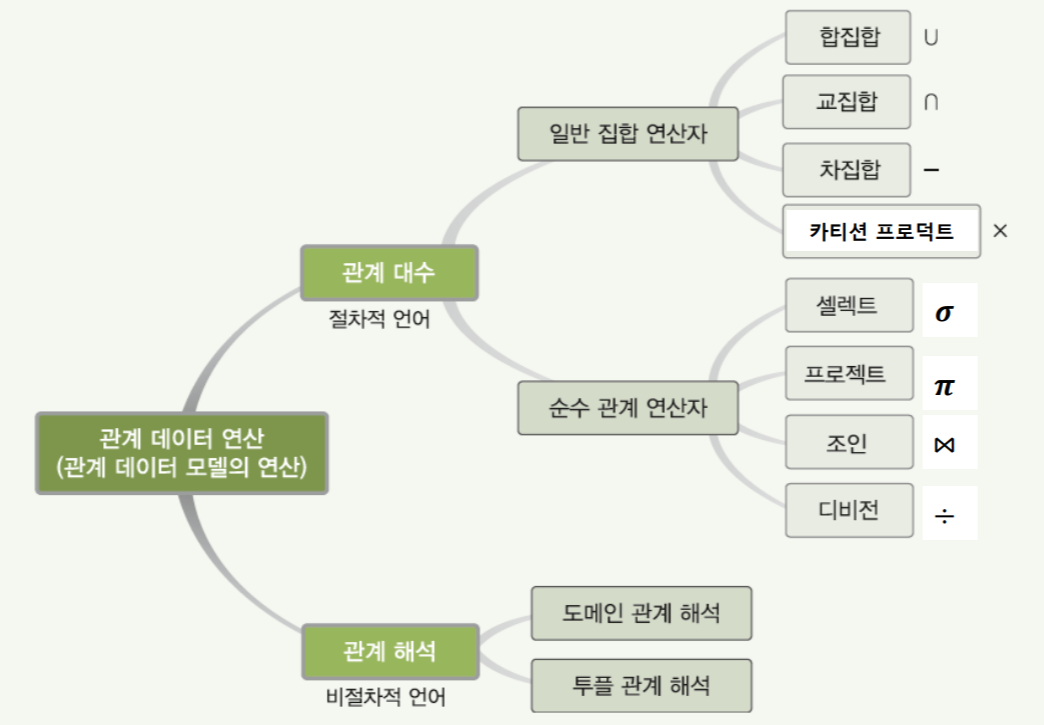

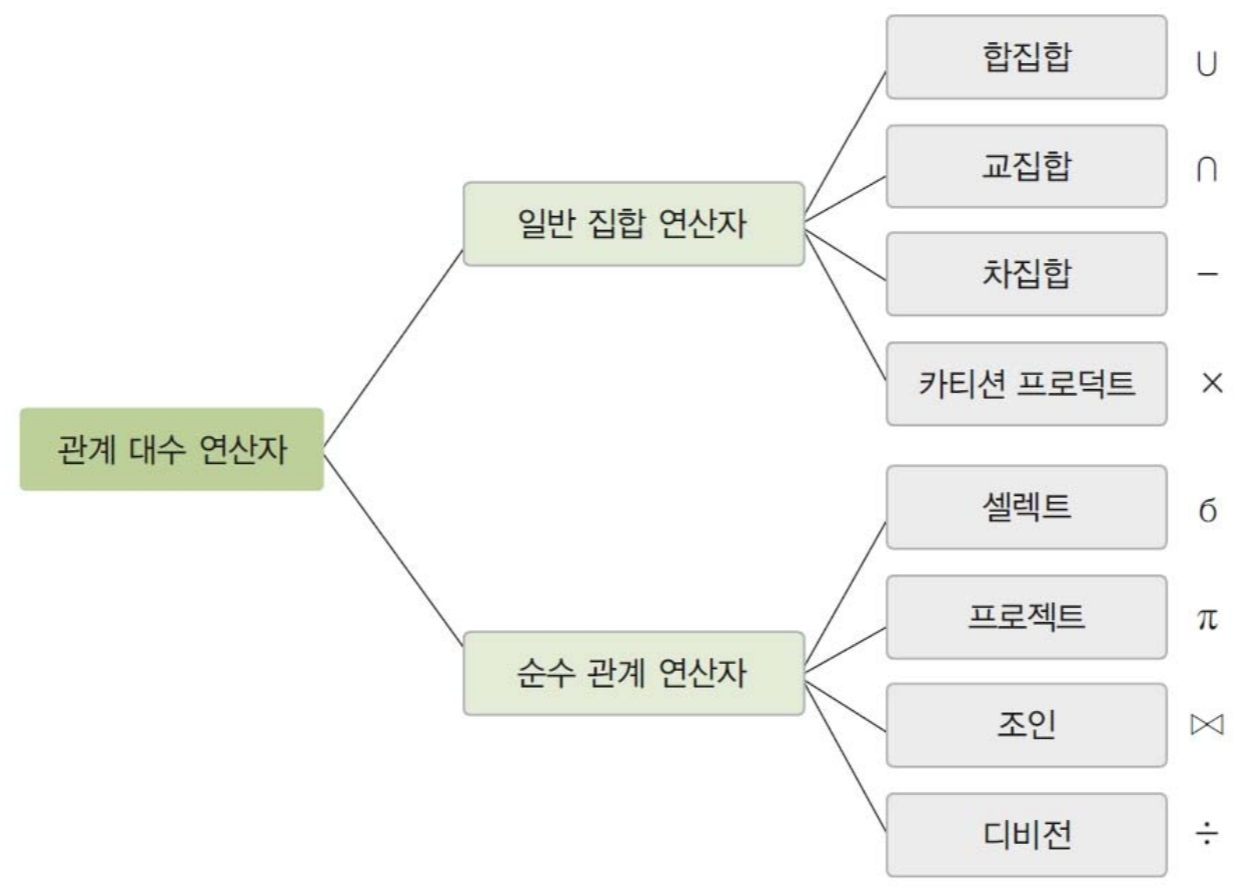
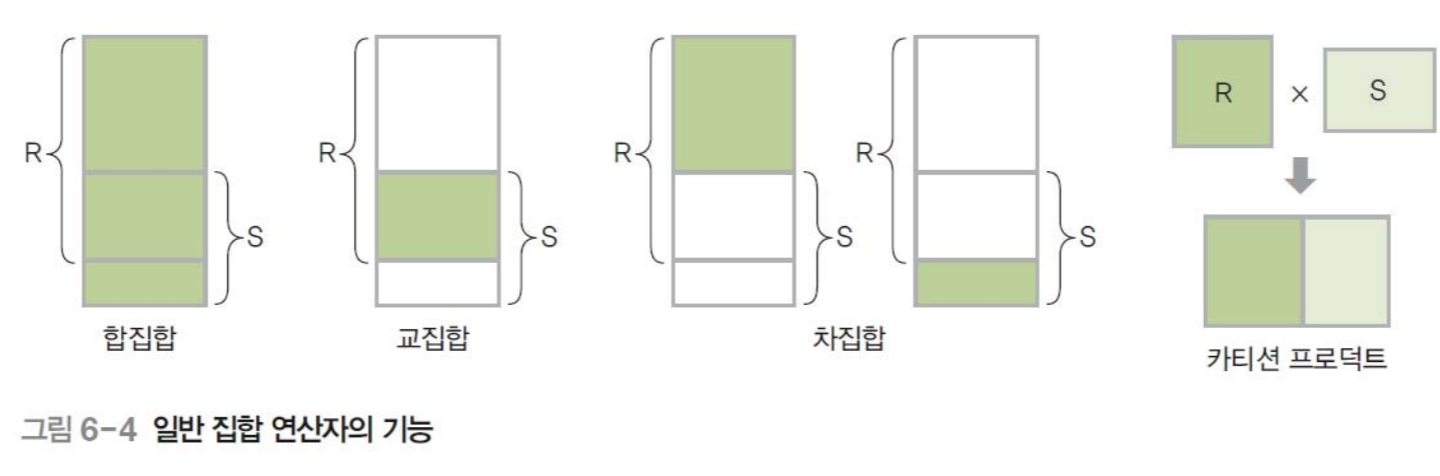
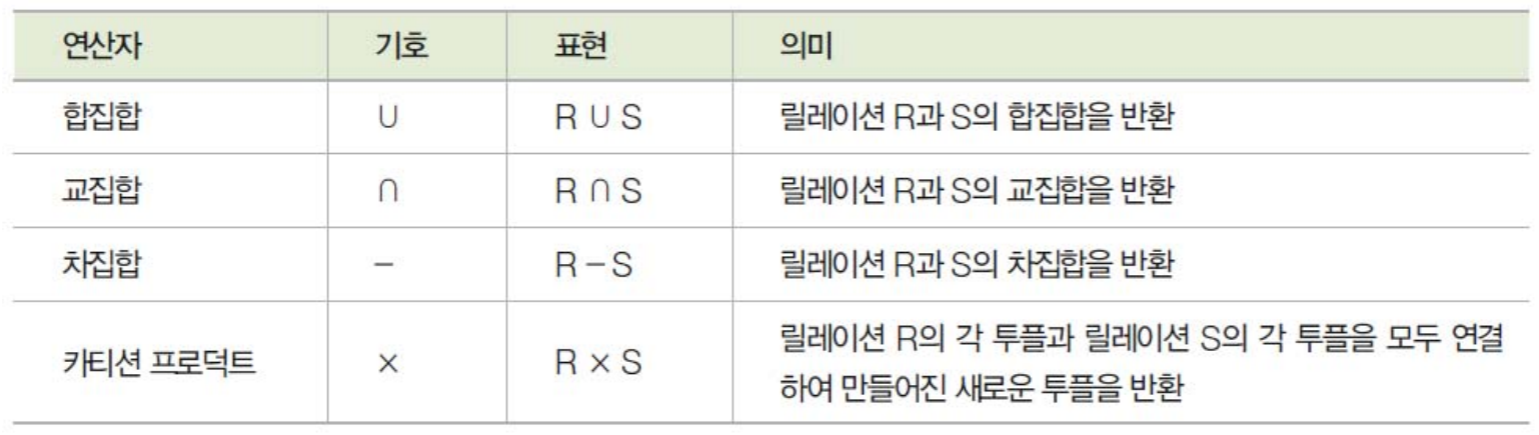


논리데이터베이스
좋은 데이터 모델의 조건
- Completeness 완전성
- 업무에 필요로 하는 모든 데이터가 데이터 모델에 정의되어 있어야함
- Non-Redundancy 중복배제
- 하나의 데이터베이스 내에 동일한 사실은 반드시 한 번만 기록하여야 함
- Business Rules 비즈니스 룰
- 수많은 업무 규칙을 데이터 모델에 표현하고 이를 해당 데이터 모델을 활용하는 모든 사용자가 그 규칙을 공유할 수 있게 제공
- Data Reusability 데이터 재사용
- 데이터의 통합성과 독립성에 대하여 충분히 고려
- Stability and Flexibility 안정성 및 활용성
- 확장성을 담보하기 위해서는 데이터 관점의 통합 불가피
- Elegance 간결성
- 합리적으로 잘 정리된 데이터를 통합하여 데이터의 집합을 정의하고, 이를 데이터 모데로 잘 표현하여 활용
- Communication 의사소통
- 데이터 분석 과정에서 도출되는 많은 업무 규칙은 데이터 모델에 개체, 서브타입, 속성, 관계등의 형태로 최대한 자세하게 표현되어야 함
- Integration 통합성
- 동일한 성격의 데이터를 한 번만 정의하기 위해 공유 데이터에 대한 구조를 여러 업무 영역에서 공동으로 사용하기 용이하게 해야 함
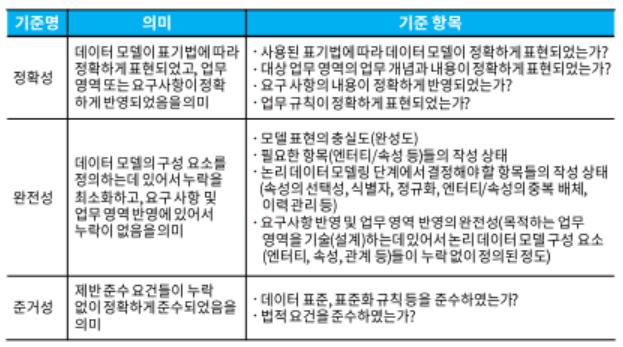
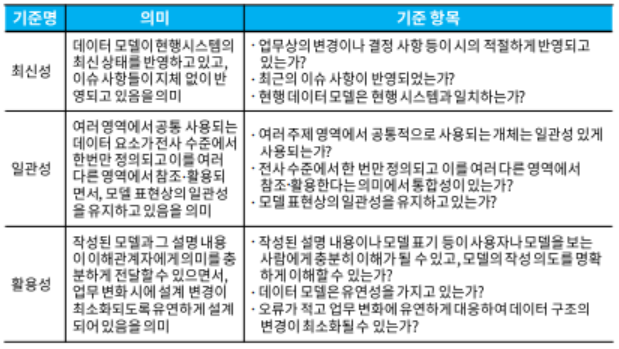
데이터 모델 품질 검증 기준