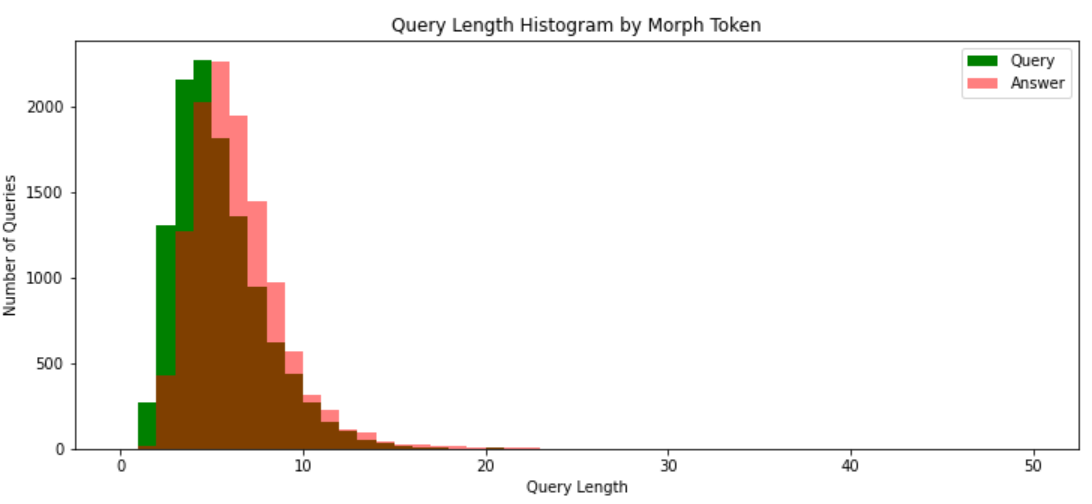
query_morph_tokenized_sentences = [okt.morphs(s.replace(' ', '')) for s in query_sentences] query_sent_len_by_morph = [len(t) for t in query_morph_tokenized_sentences]
answer_morph_tokenized_sentences = [okt.morphs(s.replace(' ', '')) for s in answer_sentences] answer_sent_len_by_morph = [len(t) for t in answer_morph_tokenized_sentences]
for s in query_sentences: for token, tag in okt.pos(s.replace(' ', '')): if tag == 'Noun'or tag == 'Verb'or tag == 'Adjective': query_NVA_token_sentences.append(token)
for s in answer_sentences: temp_token_bucket = list() for token, tag in okt.pos(s.replace(' ', '')): if tag == 'Noun'or tag == 'Verb'or tag == 'Adjective': answer_NVA_token_sentences.append(token) query_NVA_token_sentences = ' '.join(query_NVA_token_sentences) answer_NVA_token_sentences = ' '.join(answer_NVA_token_sentences)
워드클라우드 활용해 어휘 빈도 분석
NanumGothic.ttf 한글 폰트 설정
질문
1 2 3 4 5 6
from wordcloud import WordCloud query_wordcloud = WordCloud(font_path= DATA_IN_PATH + 'NanumGothic.ttf').generate(query_NVA_token_sentences)
data = pd.read_csv(DATA_IN_PATH + 'ChatBotData.csv', encoding='utf-8')
print(data.head())
Q
A
label
0
12시 땡!
하루가 또 가네요.
1
1지망 학교 떨어졌어
위로해 드립니다.
2
3박4일 놀러가고 싶다
여행은 언제나 좋죠.
3
3박4일 정도 놀러가고 싶다
여행은 언제나 좋죠.
4
PPL 심하네
눈살이 찌푸려지죠.
문장 전체에 대한 분석
데이터 길이를 분석
질문과 답변 모두 길이에 대해 분석하기 위해 두 데이터를 하나의 리스트로 만들기
1
sentences = list(data['Q']) + list(data['A'])
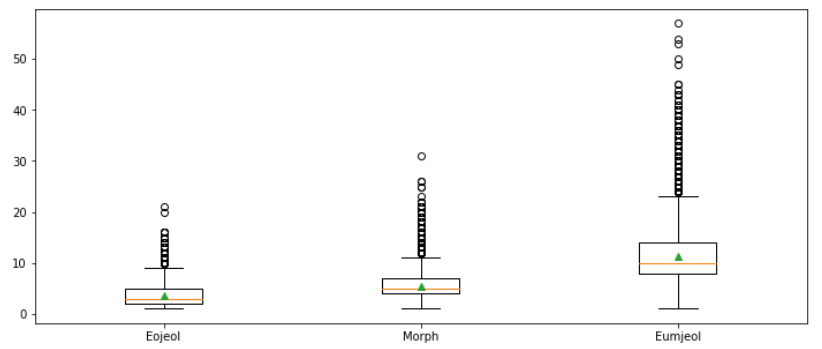
세 가지 기준으로 분석을 진행
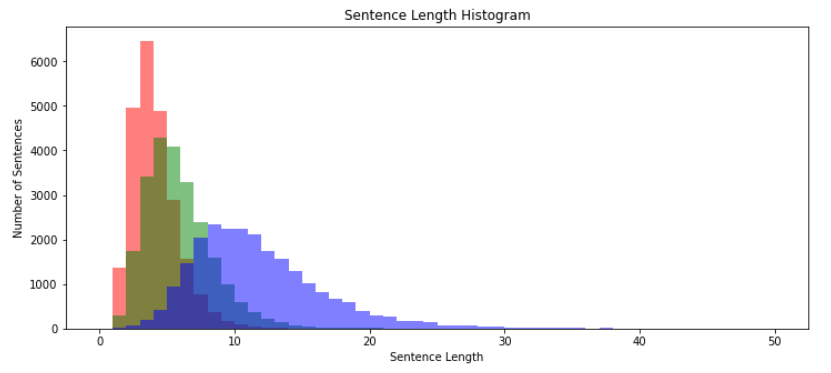
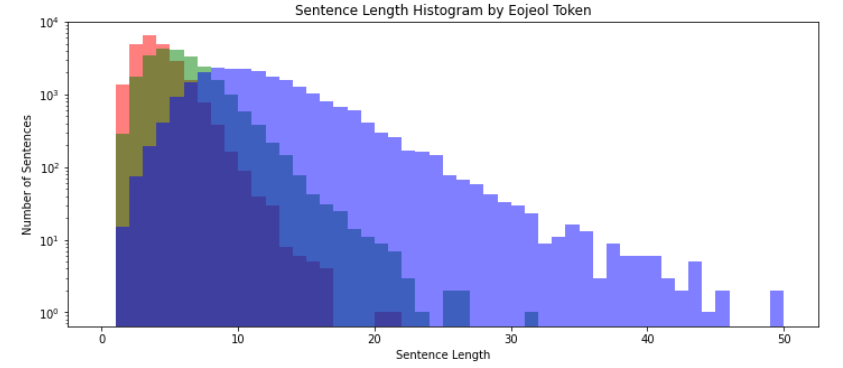
문자 단위의 길이 분석 (음절)
문자 하나하나를 생각하자
단어 단위의 길이 분석 (어절)
띄어쓰기 단위로 생각하자
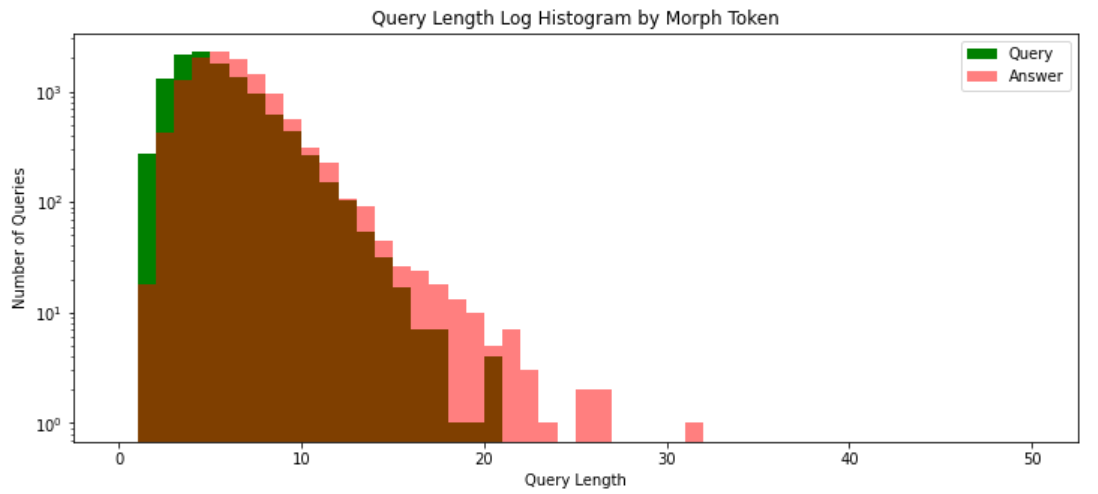
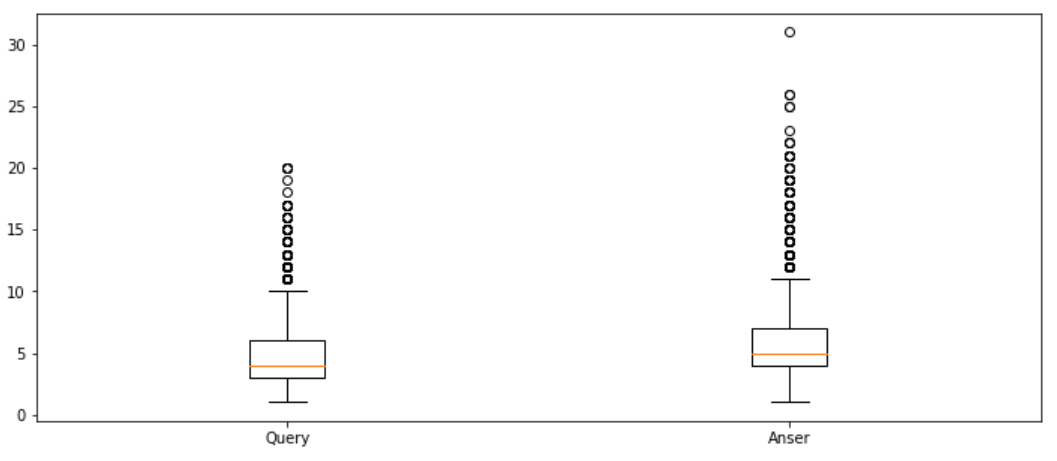
형태소 단위의 길이 분석
어절과 음절 사이로 생각하자
최소 단위를 의미
ex) 나는 학생이다.
음절 : “나”, “는”, “학”, “생”, “이”, “다”
어절 : “나는”, “학생이다”
형태소 : “나”, “는”, 학생", “이다”
토크나이징
KoNLPy 사용
1 2 3 4 5 6 7 8
tokenized_sentences = [s.split() for s in sentences] sent_len_by_token = [len(t) for t in tokenized_sentences] sent_len_by_eumjeol = [len(s.replace(' ', '')) for s in sentences]
okt = Okt()
morph_tokenized_sentences = [okt.morphs(s.replace(' ', '')) for s in sentences] sent_len_by_morph = [len(t) for t in morph_tokenized_sentences]