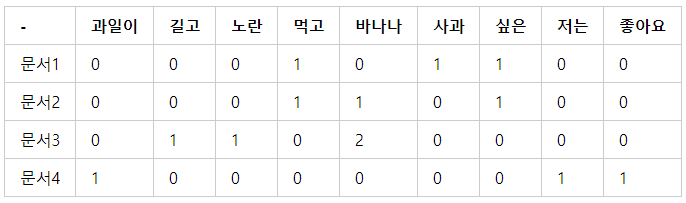



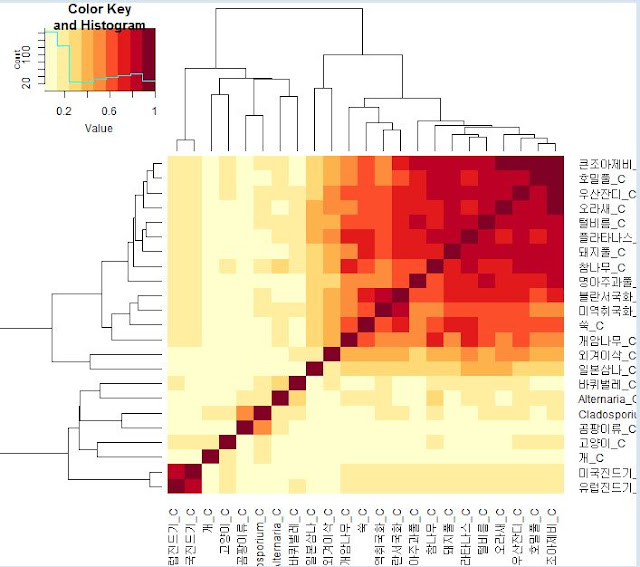

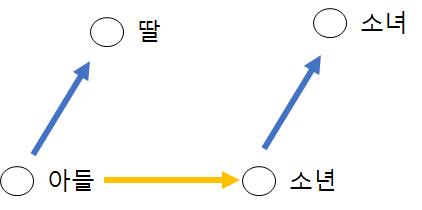



1.4.1 환경소개
- Ubuntu 16.04.5
- Python 3.5.2
- Tensorflow 1.12.0
도커 구성하기
본인은 Synology NAS를 사용하고 있으므로 NAS에서 docker 환경을 구성하는 방법을 포스팅하려고 한다.
혹 NAS가 없는 경우 책에는 AWS로 하는 방법을 소개했으니 참고하자.
도커이미지
1 | $ uname -a #ubuntu 환경 확인 |
1 | root@docker-NLG:/# apt upgrade |
pip3 라고 command에 쳤을 때 뭐라뭐라 길게 나오면 성공!
더 정확하게 확인하려면
1 | root@docker-NLG:/# pip3 --version |
1 | root@docker-NLG:/# pip3 install --upgrade pip |
도커 다운을 위한 패키지 설치
안된다면 앞에 sudo를 붙여보시길…
1 | apt install apt-transport-https |
apt-transport-https : 패키지 관리자가 https를 통해 데이터 및 패키지에 접근할 수 있도록 한다.
ca-certificates : ca-certificate는 certificate authority에서 발행되는 디지털 서명. SSL 인증서의 PEM 파일이 포함되어 있어 SSL 기반 앱이 SSroot@docker-NLG:/# pip3 --version L 연결이 되어있는지 확인할 수 있다.
curl : 특정 웹사이트에서 데이터를 다운로드 받을 때 사용
software-properties-common : *PPA를 추가하거나 제거할 때 사용한다.
curl 명령어로 도커 다운받기 && repository에 경로 추가하기
1 | root@docker-NLG:/# curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt |
curl 명령어의 옵션
f : HTTP 요청 헤더의 contentType을 multipart/form-data로 보낸다.
s : 진행 과정이나 에러 정보를 보여주지 않는다.(–silent)
S : SSL 인증과 관련있다고 들었는데, 정확히 아시는 분 있다면 댓글 부탁!
L : 서버에서 301, 302 응답이 오면 redirection URL로 따라간다.
apt-key : apt가 패키지를 인증할 때 사용하는 키 리스트를 관리한다. 이 키를 사용해 인증된 패키지는 신뢰할 수 있는 것으로 간주한다. add 명령어는 키 리스트에 새로운 키를 추가하겠다는 의미이다.
add-apt-repository : PPA 저장소를 추가해준다. apt 리스트에 패키지를 다운로드 받을 수 있는 경로가 추가된다.
docker 패키지가 검색되는지 확인
1 | root@docker-NLG:/# apt-get update |
apt update : 저장소의 패키지 갱신
도커 설치하기 && ubuntu를 도커그룹으로 입력
1 | root@docker-NLG:/# apt-get install docker-ce |
nvidia-docker 설치
위의 단계까지 끝내면 일반적인 도커 기능들을 이용하실 수 있습니다. 하지만 NVIDIA의 GPU를 이용하시면서 여러 환경의 CUDA Tookit을 이용하실 경우 nvidia-docker라는 확장 기능을 추가하시면 보다 편리하게 사용하실 수 있습니다.
nvidia-docker를 설치하고자 하실 경우 호스트 운영체제에 먼저 NVIDIA 드라이버가 설치되어 있어야 합니다. NVIDIA의 그래픽카드 또는 GPU를 사용하지 않는 경우 이 과정을 진행하고 도커 설치과정을 끝내실 수 있습니다.
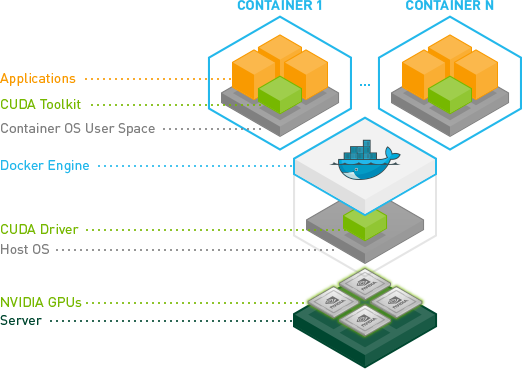
우분투에서 NVIDIA 드라이버 설치 방법
1 | root@docker-NLG:/# curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey|apt- |
nvidia-docker 실행
1 | root@docker-NLG:/# apt-get install -y nvidia-container-toolkit |
도커실행하기
1 | root@docker-NLG:/home# git clone https://github.com.rastgo/embedding |
오픈소스링크
TensorFlow : https://www.tensorflow.org
Gensim : https://radimrehurek.com/gensim
FastText : https://fasttext.cc
GloVe : https://nlp.stanford.edu/projects/glove
Swivel : https://github.com/tensorflow/models/tree/master/research/swivel
ELMo : https://allennlp.org/elmo
BERT : https://github.com/google-research/bert
Scikit-Learn : https://scikit-learn.org
KoNLPy : http://konlpy.org/en/latest/
Mecab : http://eunjeon.blogspot.com/
soynlp : https://github.com/lovit/soynlp
Khaiii : https://github.com/kakao/khaiii https://tech.kakao.com/2018/12/13/khaiii/
Bokeh : https://docs.bokeh.org/
sentencepiece : https://github.com/google/sentencepiece