

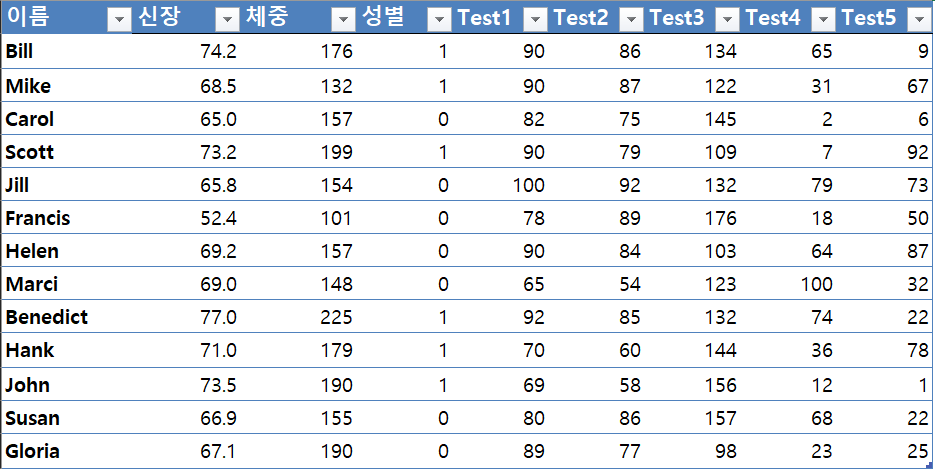
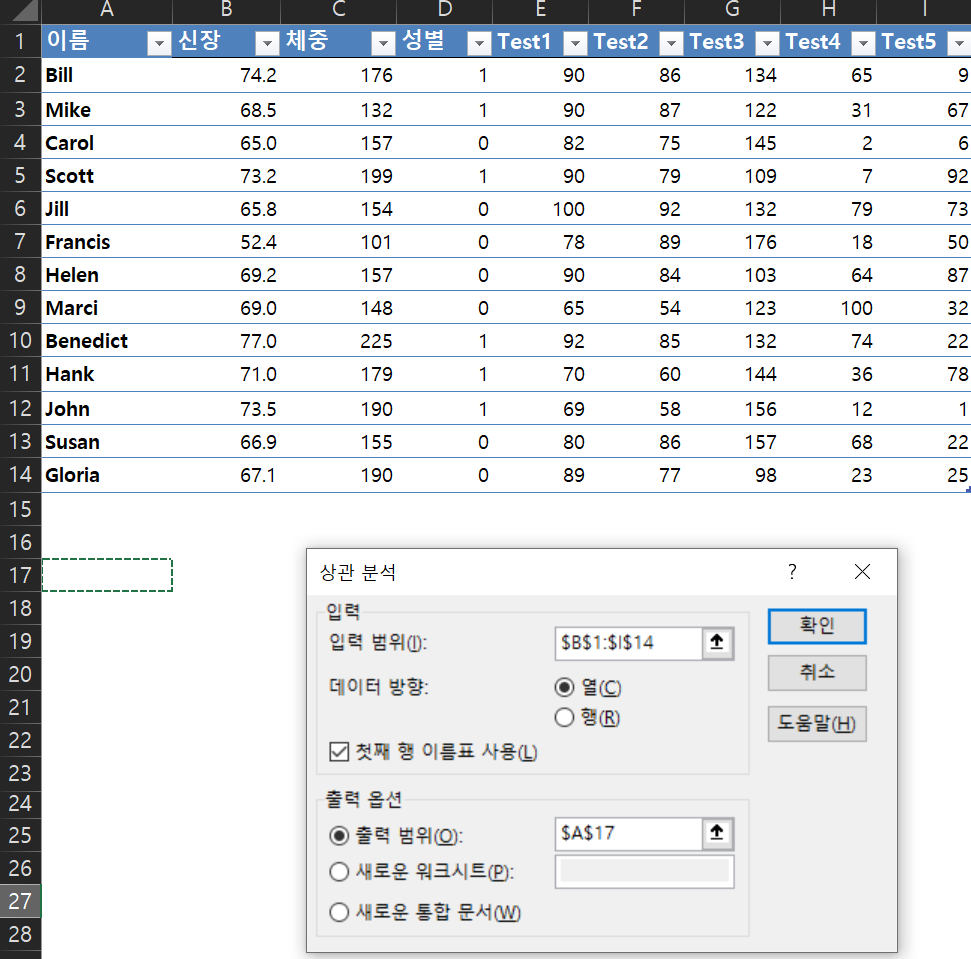
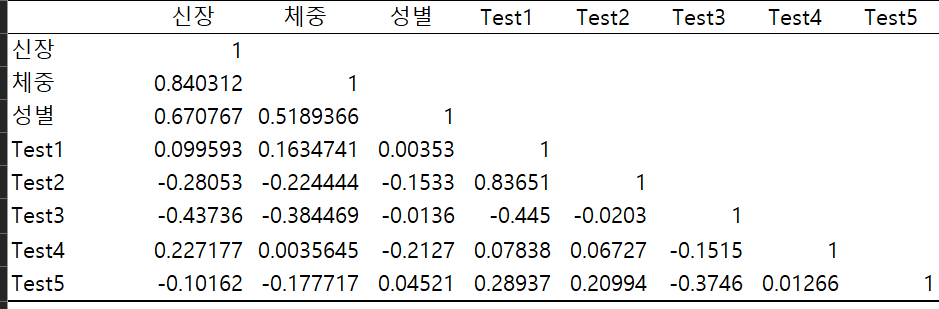


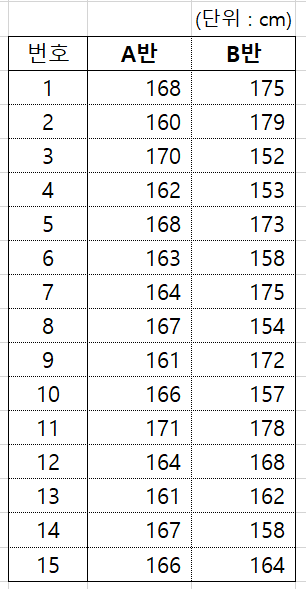
주어진 신장 데이터의 기술통계를 구하시오
분석도구를 활용한 방법
- 분석도구 설정
- '파일’탭
- 좌측 하단 ‘옵션’
- 좌측 하단 ‘추가기능’
- 화면 중앙에 ‘분석도구’ 선택
- 중앙 하단 ‘이동;’ 클릭
- 추가 기능 창 생성
- ‘분석도구’ 체크
- 확인
- ‘데이터’ 탭에 ‘분석’ 메뉴에 ‘데이터분석’ 확인
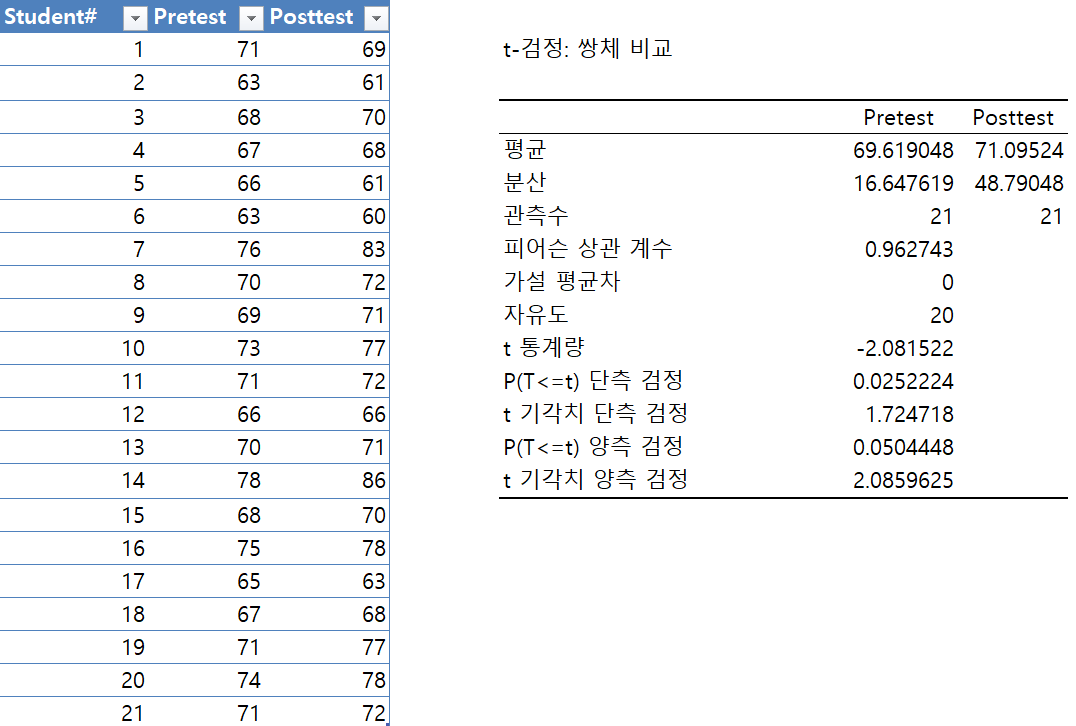
- 기술통계법
함수를 사용한 방법
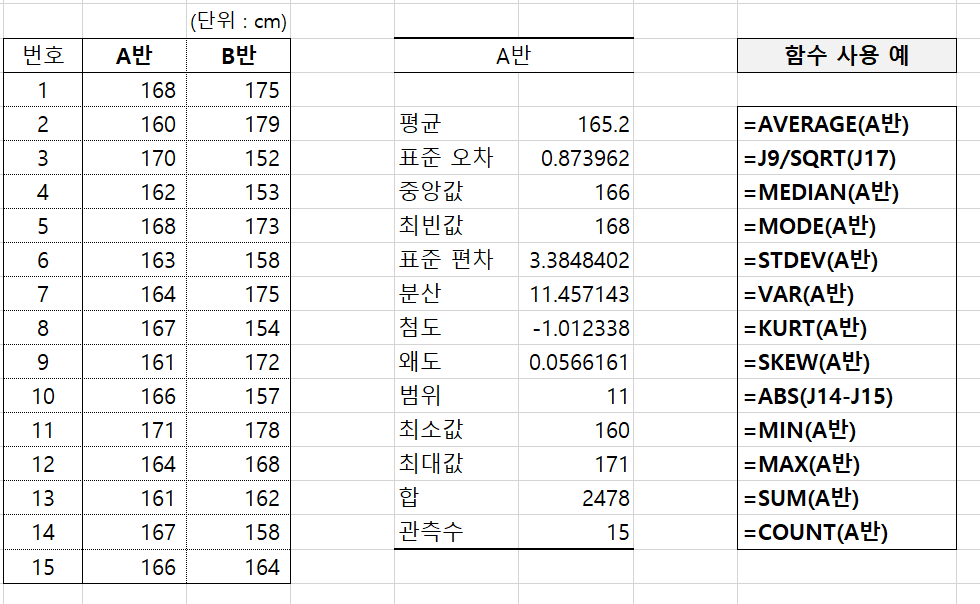
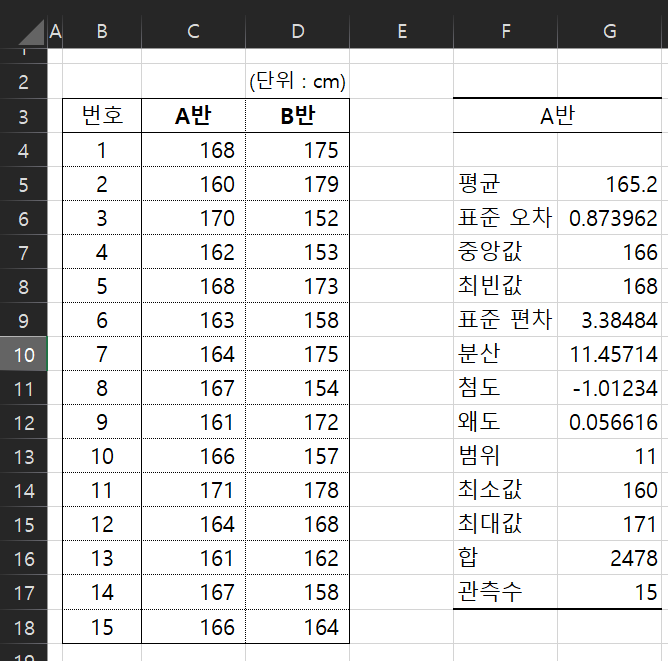
- 평균 AVERAGE()
- 표준오차 Val / SQRT()
- 중앙값 MEDIAN()
- 최빈값 MODE()
- 표준편차 STDEV()
- 분산 VAR()
- 범위 ABS()
- 최소값 MIN()
- 최대값 MAX()
- 합 SUM()
- 관측수 COUNT()
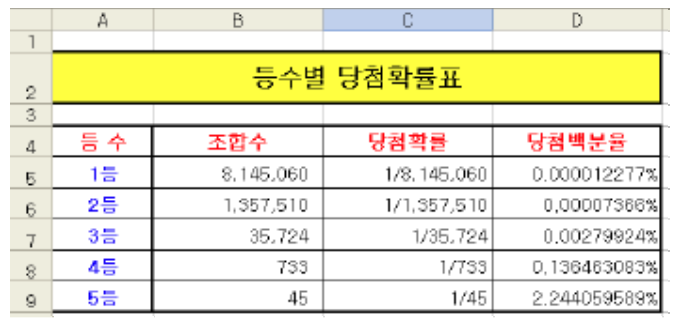
로또 6/45의 1~5등 까지의 조합수와 당첨확률을 구하시오
- 45개의 로또 공 가운데 무작위로 6개를 뽑는다
- 6개의 공을 무작위로 하나씩 뽑기 때문에 순서는 고려하지 않아도됨
- 해결방법
1등 : 모두 당첨 -> 45개 공에서 순서 상관없이 6개가 한 번에
= COMBIN(45,6) = PERMUT(45,6) / FACT(6)
2등 : 5개 당첨 -> 6개 중에서 5개가 맞고 나머지 1개는 보너스 번호
= COMBIN(45,6) / COMBIN(6,5) _ COMBIN(1,1)
3등 : 5개 당첨 -> 6개 중에서 5개가 맞고 보너스 1개를 제외한 38개 중에 1개가 포함
= COMBIN(45,6) / (COMBIN(6,5) _ COMBIN(39,1))
4등 : 6개 중 4개 포함하고 39개 중에 2개 포함
= COMBIN(45,6) / (COMBIN(6,4) _ COMBIN(39,2))
5등 : 6개 중 3개 포함하고 39개 중에 3개 포함
= COMBIN(45,6) / (COMBIN(6,3) _ COMBIN(39,3)) - 결과
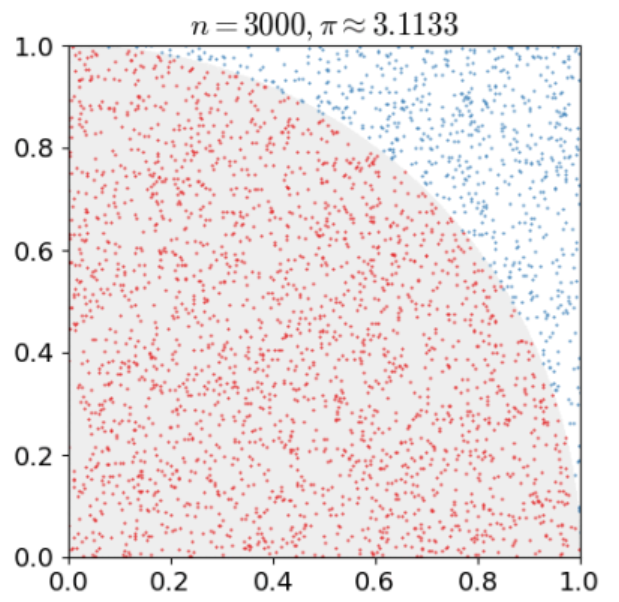
몬테카를로 시뮬레이션을 사용하여 원주율을 구하시오
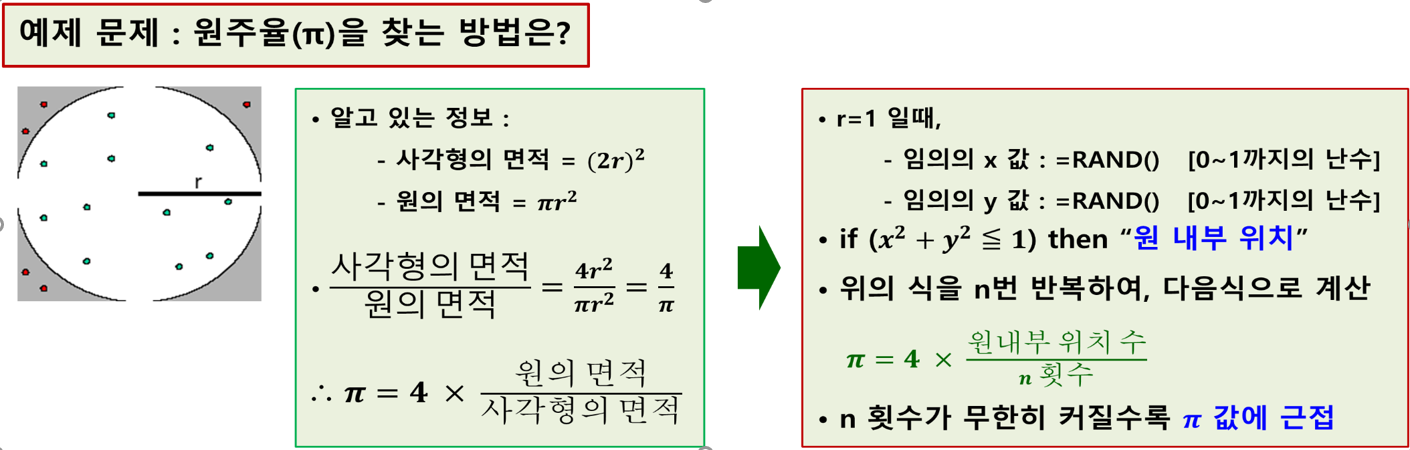
- 알고 있는 정보
- 사각형의 면적 : (2r)^2
- 원의 면적 : πr^2
- 사각형의 면적/원의 면적 = 4r^2 / πr^2 = 4/π
- π = 4 * 원의 면적 / 사각형의 면적
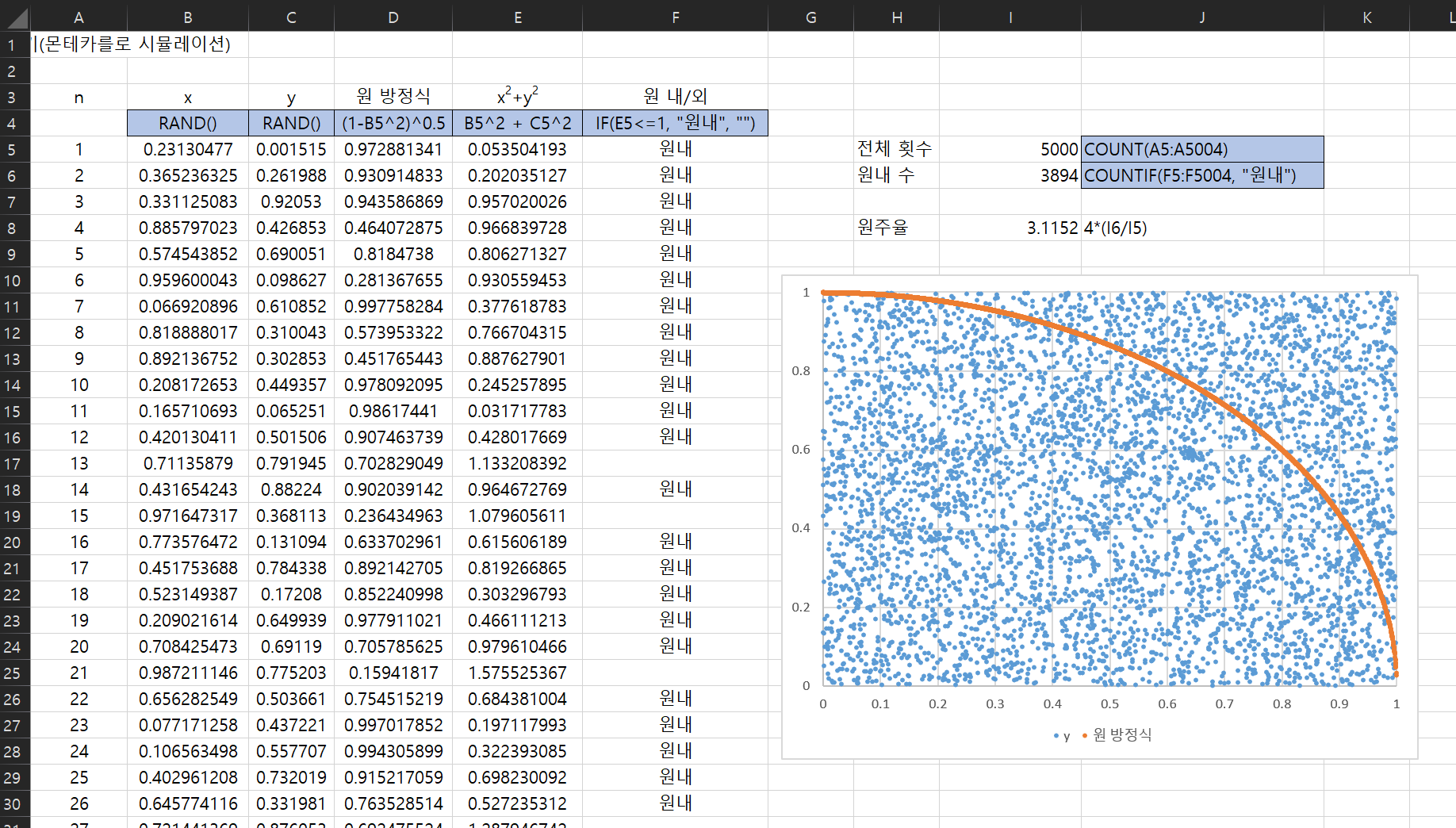
- 랜덤으로 출력할 x, y
= RAND() : 0~1까지의 난수 - 원의 방정식
x^2 + y^2 = 1 이므로 y = (1-x2)0.5
위 값이 원 내에 있는지 즉 1보다 작은지 확인 IF(Val<=1.“원내”,“원밖”) - 원내 수 세기
COUNTIF(범위, “원내”)

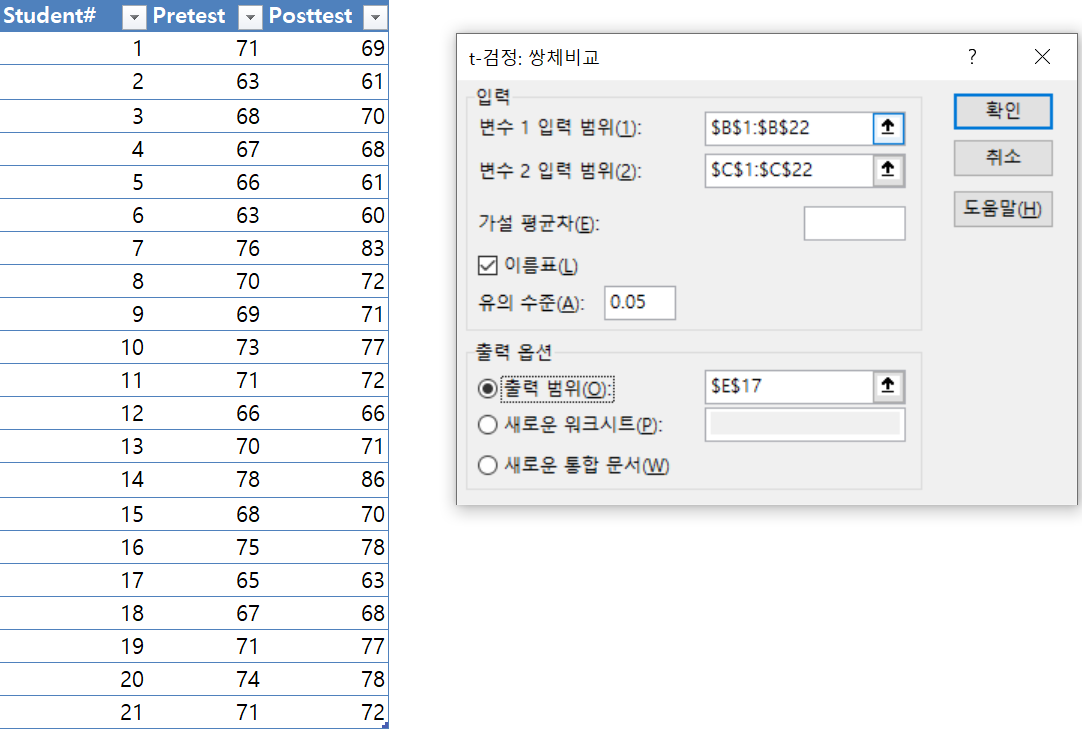
한 중학생의 시험점수를 이용하여 등수를 구하시오(전체성적평균과 표준편차는 제공)
문) 우리집 막내A 는 중학교 2학년에 재학중이다. 이번 중간고사 시험결과가 학교로부터 우편으로 배달되었다. 시험결과 안내는 A의 등수가 아니라 표로 제시되었다. 2학년 전체의 시험성적이 정규분포를 나타낼때 A의 등수는?
| A의평균점수 | 2학년 평균점수 | 2학년 표준편차 | 2학년 학생 수 |
|---|---|---|---|
| 81.5 | 78.6 | 16.4 | 347 |
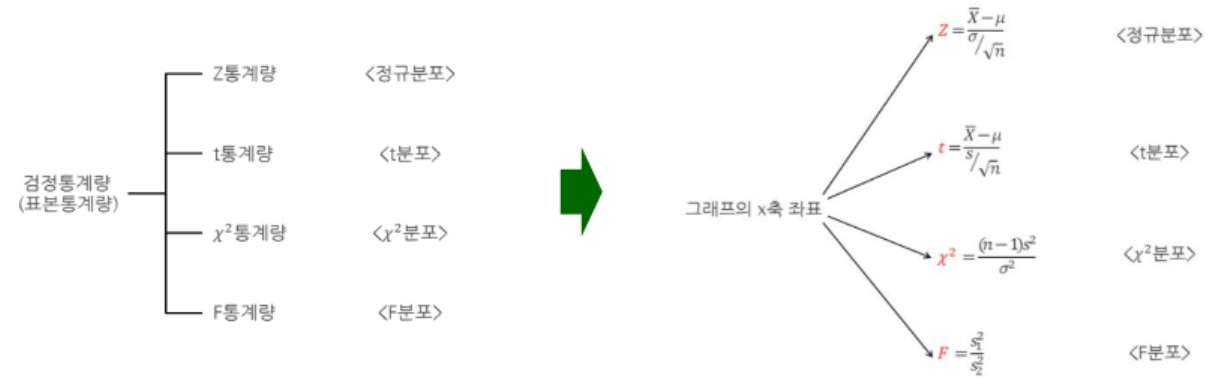
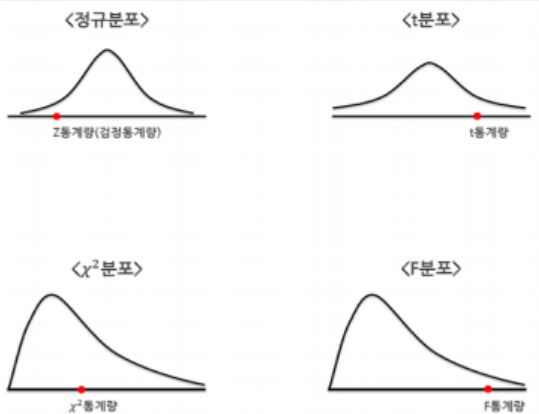
- 정규분포를 알고 가야한다.
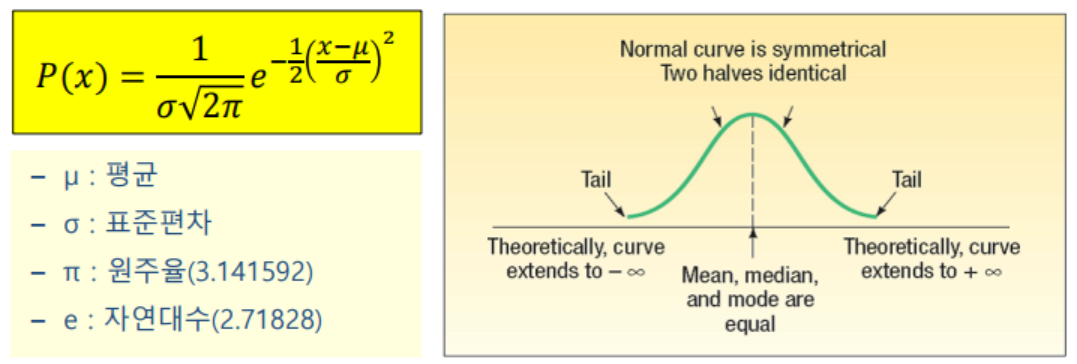
- 표준정규분포는 정규분포에서 평균이 0 표준편차가 1인 조건이 추가된다
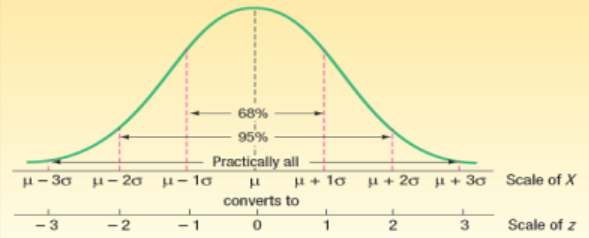
평균에 가장 많은 수가 몰려있고 평균을 기점으로 좌우 대칭이고 서서히 분포가 낮아지는 종모양이다. - z값을 구하자
점수에서 평균을 빼고 그것을 표준 편차로 나누면 z이다
z = (81.5 - 78.6) / 16.4 = 0.1768 - z에 대응하는 값을 정규분포표에서 찾기
음수라면 절대값을 취한다
0.1768이므로 반올림해서 0.18로 하겠다
대응값 : 0.0714 를 찾았다 - 등수구하기
대응값(면적)을 평균이 아닌 오른쪽 면적으로 바꾸어주고 전체 인원만큼 곱해야한다
z가 양수라면 0.5-(대응값)
z가 음수라면 대응값+0.5
0.18은 양수이므로 0.5 - 0714 = 0.4286
0.4286에 전체 학생수를 곱한다
0.43 * 347 = 148.724
149등이 추정 등수이다.
참고링크