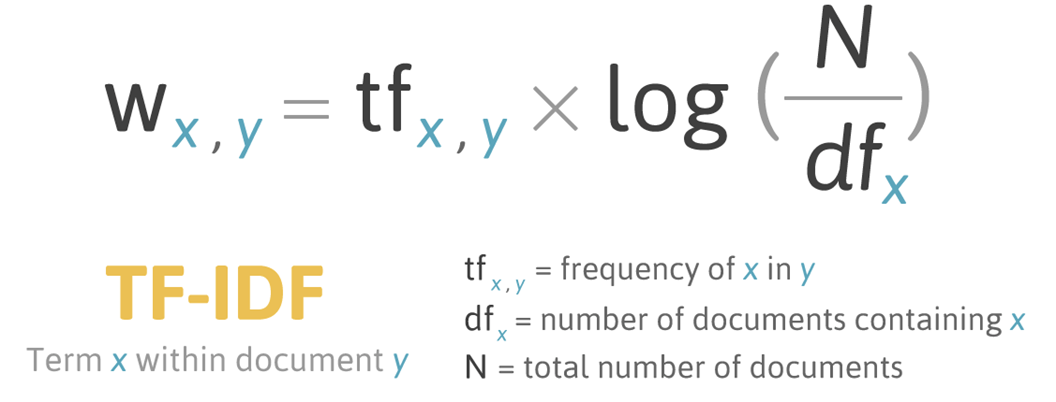자연어 처리에서 분포 distribution란 특정 범위, 즉 윈도우 내에 동시에 등장하는 이웃 단어 또는 문맥의 집합을 가리킨다. 개별 단어의 분포는 그 단어가 문장 내에서 주로 어느 위치에 나타나는지, 이웃한 위치에 어떤 단어가 자주 나타나는지에 따라 달라진다. 어떤 쌍이 비슷한 문맥 환경에서 자주 등장한다면 그 의미 도한 유사할 것이라는 게 분포 가정 ** distributional hypothesis**의 전제다.
예컨데 한국어의 빨래, 세탁이라는 단어의 의미를 전혀 모른다고 하자. 두 단어의 의미를 파악하기 위해서는 이들 단어가 실제 어떻게 쓰이고 있는지 관찰을 해야한다. 두 단어는 타깃 단어 ** target word**이고 청소, 물 등은 그 주위에 등장한 문맥 단어가 된다
특기는 자칭 청소와 빨래지만 요리는 절망적
재를 우려낸 물로 빨래 할 때 나
찬 물로 옷을 세탁한다.
세탁, 청소, 요리와 기사는
이웃한 단어들이 서로 비슷하기 때문이다. 빨래가 청소물 과 같이 등장하는 경향을 미루어 짐작해볼 때 이들끼리도 직간접적으로 관계를 지닐 가능성이 낮아보이지는 않는다. 그럼에도 개별 단어의 분포 정보와 그 의미 사이에는 논리적으로 직접적인 연관성은 사실 낮다. 다시 말해 분포 정보가 곧 의미라는 분포 가정에 의문접이 발생한다.
2.4.2 분포와 의미(1) : 형태소
형태소** morpheme란 의미를 가지는 최소 단위를 말한다. 더 쪼개면 의미를 잃어버리는 것이다.
예를 들어 철수가 밥을 먹었다 라고 한다면 형태소 후보는 철수, 밥, 이다.
조금 더 깊게 분석해보자. 계열관계 ** paradigmatic relation가 있다.
계열 관계는 해당 형태소 자리에 다른 형태소가 '대치’되어 쓰일 수 있는 가를 따지는 것이다. 예컨데 철수 대신에 영희가 올 수 있고 밥대신 빵을 쓸 수 있다. 이를 근거로 형태소 자격을 부여한다.
특정 타깃 단어 주변의 문맥 정보를 바탕으로 형태소를 확인한다는 이야기와 일맥상통한다.
말뭉치의 분포 정보와 형태소가 밀접한 관계를 이루고 있다.
2.4.3 분포와 의미(2) : 품사
품사란 단어를 문법적 성질의 공통성에 따라 언어학자들이 몇 갈래로 묶어 놓은 것이다.
기능
의미
형식
위 세가지를 기준으로 분류한다.
기능
한 단어가 문장 가운데서 다른 단어와 맺는 관계를 가르킨다. 깊이높이는 문장에서 주어로 쓰이고 깊다높다는 서술어로 사용되고 있다.
의미
단어의 형식적 의미를 나타낸다. ``깊이높이를 하나로 묶고깊다높다`를 같은 군집으로 넣을 수 있다. 품사에서는 어휘적 의미보다 형식적 의미가 중요하다. 다시말해 어떤 단어가 사물의 이름을 나타내는가, 그렇지 않으면 움직임이나 성실, 상태를 나타내느냐 하는 것이다.
형식
단어의 형태적 특징을 의미한다. 깊이높이는 변화하지 않는다. 깊었다높았다깊겠다높겠따 따위와 같이 어미가 붙어 여러 가지 모습으로 변화를 일으킬 수 있다.
그러나 예외가 있다. 공부공부하다 두 개를 분류하려면 공부는 명사이지만 우리는 동작이라는 여지를 알고 있다.
품사 분류에서 가장 중요한 기준은 기능이다. 해당 단어가 문장 내에서 점하는 역할에 초점을 맞춰 품사를 분류한다는 것이다.
형태소의 경계를 정하거나 품사를 나누는 것과 같은 다양한 언어학적 문제는 말뭉치의 분포 정보와 깊은 관계를 갖고 있다. 이로인하여 분포 정보를 함축한다면 해당 벡터에 해당 단어의 의미를 자연스레 내재시킬 수 있는 것이다.
2.4.4 점별 상호 정보량
점별 상호 정보량은 두 확률변수사이의 상관성을 계량화하는 단위다. 두 확률변수가 완전히 독립인 경우 그 값이 0이 된다. 독립이라고 하면 A가 나타나는 것이 단어 B의 등장할 확률에 전혀 영향을 주지 않고, 단어 B등장이 단어 A에 영향을 주지 않는 경우를 가리킨다.
두 단어의 등장이 독립일 때 대비해 얼마나 자주 같이 등장하는지를 수치화한 것이다
언어 모델 ** language model**이란 단어 시퀀스에 확률을 부여하는 모델이다.
단어의 등장 순서를 무시하는 백오브워즈와 달리 언어 모델은 시퀀스 정보를 명시적으로 학습한다.
단어가 n개 주어진 상황이라면 언어 모델은 n개 단어가 동시에 나타날 확률, 즉 P라는 것을 반환한다. 통계 기반의 언어 모델은 말뭉치에서 해당 단어 시퀀스가 얼마나 자주 등장하는지 빈도를 세어 학습한다. 이렇게 되면 주어진 단어 시퀀스 다음 단어는 무엇이 오는게 자연스러운지 알 수 있다.
n-gram이란 n개 단어를 뜻하는 용어이다. 난폭,운전눈_뜨다 등은 2-gram 또는 bigram이라는 말을 쓴다. 누명, 을, 쓰다 는 3-gram 혹은 trigram이라고 쓴다. 경우에 따라서 n-gram은 n-gram에 기반한 언어 모델을 의미하기도 한다. 말뭉치 내 단어들을 n개씩 묶어서 그 빈도를 학습했다는 뜻이다.
예컨데 내, 내_마음 말뭉치는 빈도가 많지만 내_마음_속에_영원히_기억될_최고의_명작이다 라는 말뭉치가 한 번도 없을 수 있다. 이럴 때에는 말뭉치로 학습한 언어 모델은 해당 표현이 나타날 확률을 0으로 부여하게 된다.
문법적으로나 의미적으로 결함이 없는 훌륭한 한국어 문장임에도 해당 표현을 말이 되지 않는 문장으로 취급할 수 있다는 것이다.
내_마음_속에_영원히_기억될_최고의 라는 표현 다음에 명작이다라는 단어가 나타날 확률은 조건부확률 ** conditional probability**의 정의를 활용해 최대우도추정법 으로 유도한다.
앞에서 배운 n-gram을 사용해보자. 직전 n-1개 단어의 등장 확률로 전체 단어 시퀀스 등장 확률을 근사하는 것이다. 이말을 다시 해석하면 한 상태** state**의 확률은 그 직전 상태에만 영향을 받는 것이다. 마코프 가정 Markov assumption에 기반한 것이다.
일반화를 시킨다면 다음과 같다. 바이그램모델에서는 1개만 참고하지만 일반화를 시키면 전체 단어 시퀀스 등장 확률 계산시 직전 n-1개 단어의 히스토리를 본다
P(Wn∣W(n−1)=Freq(W(n−1))Freq(W(n−1,W(n))
그러나 데이터에 한 번도 등장하지 않는 n-gram이 존재할 때 예측 문제가 발생할 수 있다. 처음 보는 단어를 본다면 그 확률은 0으로 보기 때문이다.
이를 위해서 백오프** back-off**, 스무딩 ** smoothing**등의 방식이 제안된다.
백오프란 n-gram등장 빈도를 n보다 작은 범위의 단어 시퀀스 빈도로 근사하는 방식인데, n을 크게 하면 할 수록 등장하지 않은 케이스가 많아질 가능성이 높기 때문이다. 내_마음_속에_영원히_기억될_최고의_명작이다는 7-gram에서는 0이지만 N을 4로 내린다면 달라진다.
스무딩이란 등장 빈도 표에 모두 K만큼 더하는 것이다. 높은 빈도를 가진 문자열 등장 확률을 일부 깎고 학습 데이터에 전혀 등장하지 않은 케이스들에는 일부 확률을 부여하게 된다.
2.3.2 뉴럴 네트워크 기반 언어 모델
뉴럴 네트워크는 입력과 출력 사이의 관계를 유연하게 포착해낼 수 있고, 그 자체로 확률 모델로 기능이 가능하기 때문에 뉴럴 네트워크로 사용한다.
1
발 없는 말이 -> [언어모델] -> 천리
뉴럴 네트워크 기반 언어 모델은 위 그림처럼 단어 시퀀스를 가지고 다음 단어를 맞추는 과정에서 학습된다. 학습이 완료되면 이들 모델의 중간 혹은 말단 계산 결과물을 단어나 문장의 임베딩으로 활용한다. 대표적인 모델은 다음과 같다.
ELMo
GPT
마스크 언어 모델 ** masked language model**은 언어 모델 기반 기법과 큰 틀에서 유사하지만 디테일에서 차이가 잇다. 문장 중간에 '마스크’를 씌워 놓고 해당 위치에 어떤 단어가 올지 예측하는 과정을 학습한다.
대게 언어 모델 기반 기법은 단어를 순차적으로 입력받아 다음 단어를 맞춰야하기 때문에 태생적으로 일방향 ** uni-directional이다. 하지만 마스크 언어 모델 기반 기법은 문장 전체를 보고 중간을 예측하기 때문에 양방향 ** bi-directional학습이 가능하다. 대표적인 모델은 다음과 같다.
수학에서 백이란 중복 원소를 허용한 집합 multiset을 뜻한다. 원소의 순서는 고려하지 않는다. 어쩌면 중복 집합과 같다.
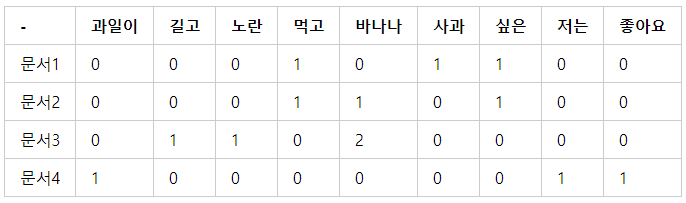
자연어 처리 분야에서는 백오브워즈 bag of words란
단어의 등장 순서에 관계없이 문서 내 단어의 등장 빈도를 임베딩으로 쓰는 기법
문장을 단어들로 나누고 이들을 중복집합에 넣어 임베딩으로 활용하는 것
저자가 생각한 주제가 문서에서의 단어 사용에 녹아 있을 것
주제가 비슷한 문서라면 단어 빈도 또는 단어 등장 역시 비슷하 것
빈도를 그대로 백오브워즈로 쓴다면 많이 쓰인 단어가 주제와 더 강한 관련을 맺고 있을 것
위 처럼 문장을 단어로 쪼개고 임의의 주머니에 넣고 뽑았을 때 등장하면 1 아니면 0을 반영한 것이다.
백오브워즈 임베딩은 단순하지만 정보 검색 ** Information Retrieval분야에서 많이 쓰인다.
사용자의 질의 ** query에 가장 적절한 문서를 보여줄 때 질의를 백오브워즈 임베딩으로 변환하고 질의와 검색 대상 문서 임베딩 간 코사인 유사도를 구해 유사도가 가장 높은 문서를 사용자에게 노출한다.
2.2.2 TF-IDF
단어 빈도 또는 등장 여부를 그대로 임베딩으로 쓰는 것에는 단점이 있다. 해당 단어가 많이 나왔다고 하더라도 문서의 주제를 가늠하기 어렵다. 이유는 다음과 같다. ‘을/를’, ‘이/가’ 같은 조사들이 한국어 문서에 등장한다. 이 것으로 문서의 주제를 추측하기 어렵다.
이런 단점을 보완하기 위해서 Term Frequency-Inverse Document Frequency이다.
단어-문서 행렬에 가중치를 계산해 행렬 원소를 바꾼다. 이 또한 단어 등장 순서는 고려하지 않는다.
결국 TF-IDF는 어떤 단어의 주제 예측 능력이 강할 수록 가중치가 커지고 그 반대의 경우 작아진다
어떤 단어의 TF가 높으면 TF-IDF 값 역시 커진다
단어 사용 빈도는 저자가 상정한 주제와 관련을 맺고 있을 거라는 가정에 기초한 것이다
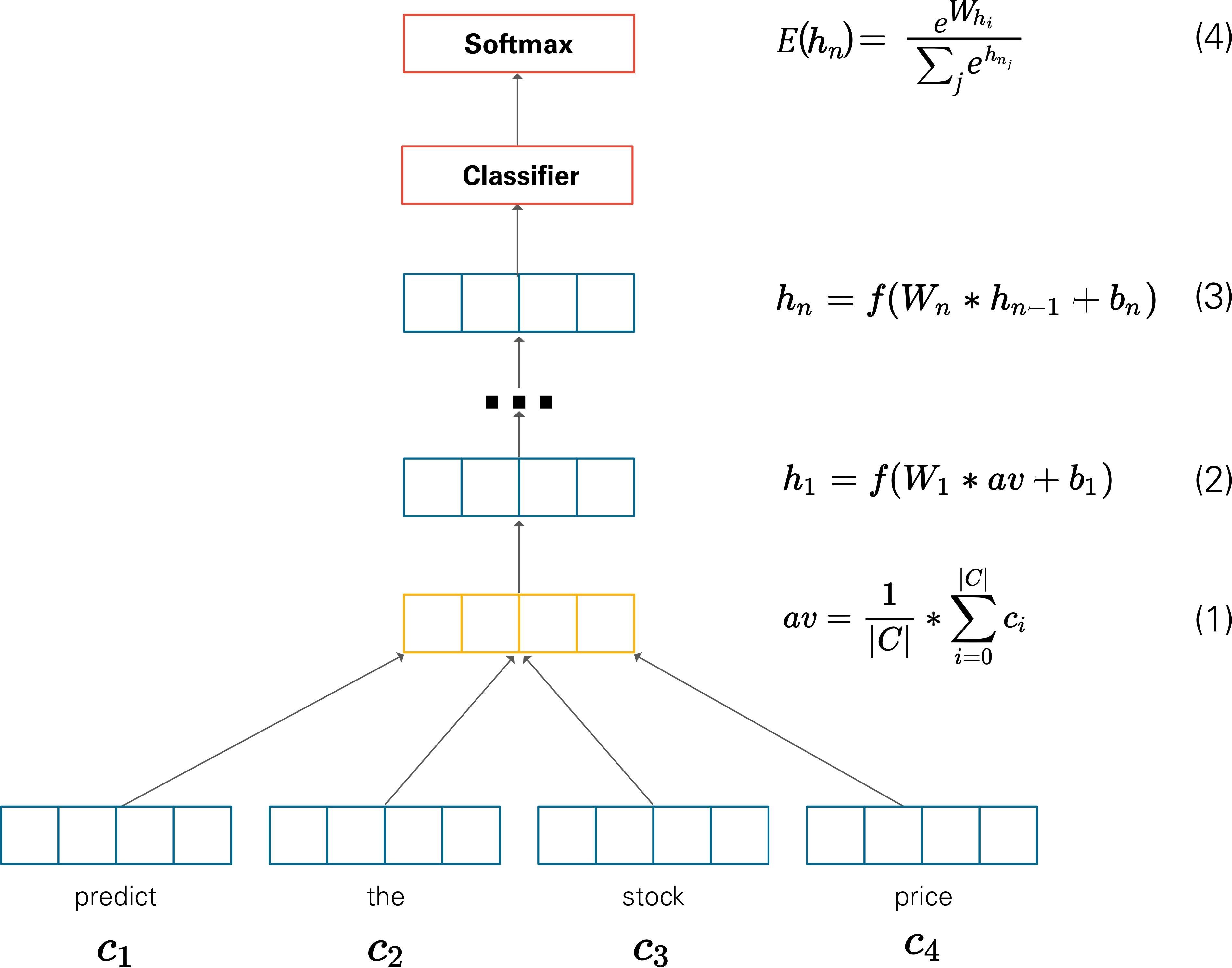
2.2.3 Deep Averaging Network
Deep Averaging Network는 백오브워즈 가정의 뉴럴 네트워크 버전이다.
예를 들어 애비는 종이었다 라는 문장이 있다면
{애비, 종, 이, 었, 다}에 속한 단어의 임베딩을 평균을 취해 만든다. 문장 내에 어떤 단어가 쓰였는지, 쓰였다면 얼마나 많이 쓰였는지 그 빈도만을 고려한다. 문장 임베딩을 입력받아 해당 문서가 어떤 범주인지 분류 classifiation 한다.
컴퓨터는 자연어를 사람처럼 이해할 수 없다. 그러나 임베딩을 활용하면 컴퓨터가 자연어를 계산하는 것이 가능해진다.
임베딩은 자연어를 컴퓨터가 처리할 수 있는 숫자들의 나열인 벡터로 바꾼 결과이기 때문이다. 컴퓨터는 임베딩을 계산/처리해 사람이 알아들을 수 있는 형태의 자연어로 출력한다.
자연어의 통계적 패턴 ** statistical pattern** 정보를 통째로 임베딩에 넣는다.
임베딩을 만들 때 쓰는 통계 정보는 3가지가 있다.
문장에 어떤 단어가 많이 쓰였는지
단어가 어떤 순서로 등장하는지
문장에 어떤 단어가 같이 나타났는지
구분
백오프워즈 가정
언어 모델
분포가정
내용
어떤 단어가 많이 쓰였는가
단어가 어떤 순으로 쓰였는가
어떤 단어가 같이 쓰였는가
대표 통계량
TF-IDF
-
PMI
대표 모델
Deep Averaging Network
ELMo, GPT
Word2Vec
언어 모델에서는 단어의 등장 순서를, 분포 가정에서는 이웃 단어를 우선시한다. 어떤 단어가 문장에서 주로 나타나는 순서는 해당 단어의 주변 문맥과 뗄래야 뗄 수 없는 관계를 가진다.
한편, 분포 가정에서는 어떤 쌍이 얼마나 자주 나타나는지와 관련한 정보를 수치화하기 위해 개별 단어 그리고 단어 쌍의 빈도 정보를 적극 활용한다.
백오브워즈 가정, 언어 모델, 분포 가정은 말뭉치의 통계적 패턴을 서로 다른 각도에서 분석하는 것이며 상호 보완적이다.
임베딩이란 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 그 일련의 과정 전체를 가리킴
임베딩을 사용하면 단어/문장 간 관련도를 계산할 수 있음
임베딩에는 믜미적/문법적 정보가 함축돼 있음
임베딩은 다른 딥러닝 모델의 입력값으로 쓰일 수 있음
임베딩 기법은 (1) 통계 기반에서 뉴럴 네트워크 기반으로 (2) 단어 수준에서 문장 수준으로 (3) 엔드투엔드에서 프리트레인/파인 튜닝 방식으로 발전해옴
임베딩 기법은 크게 행렬 분해 모델, 에측 기반 방법, 토픽 기반 기법 등으로 나눠짐
이 책이 다루는 데이터의 최소 단위는 토큰임. 문장은 토큰의 집합, 문서는 문장의 집합, 말뭉치는 문서의 집합을 가리킴. 말뭉치 > 문서 > 문장 > 토큰. 어휘 집합은 말뭉치에 있는 모든 문서를 문장으로 나누고 여기에 토크나이즈를 실시한 후 중복을 제거한 토큰들의 집합임
apt-transport-https : 패키지 관리자가 https를 통해 데이터 및 패키지에 접근할 수 있도록 한다.
ca-certificates : ca-certificate는 certificate authority에서 발행되는 디지털 서명. SSL 인증서의 PEM 파일이 포함되어 있어 SSL 기반 앱이 SSroot@docker-NLG:/# pip3 --version L 연결이 되어있는지 확인할 수 있다.
curl : 특정 웹사이트에서 데이터를 다운로드 받을 때 사용
software-properties-common : *PPA를 추가하거나 제거할 때 사용한다.
f : HTTP 요청 헤더의 contentType을 multipart/form-data로 보낸다.
s : 진행 과정이나 에러 정보를 보여주지 않는다.(–silent)
S : SSL 인증과 관련있다고 들었는데, 정확히 아시는 분 있다면 댓글 부탁!
L : 서버에서 301, 302 응답이 오면 redirection URL로 따라간다.
apt-key : apt가 패키지를 인증할 때 사용하는 키 리스트를 관리한다. 이 키를 사용해 인증된 패키지는 신뢰할 수 있는 것으로 간주한다. add 명령어는 키 리스트에 새로운 키를 추가하겠다는 의미이다.
add-apt-repository : PPA 저장소를 추가해준다. apt 리스트에 패키지를 다운로드 받을 수 있는 경로가 추가된다.
잠재 의미 분석이란 단어 사용 빈도 등 말뭉치의 통계량 정보가 들어 있는 커다란 행렬 ** Matrix에 특이값 분해 ** Singular Value Decomposition등 수학적 기법을 적용해 행렬에 속한 벡터들의 차원을 축소하는 방법
단어-문서 행렬에 잠재 의미 분석을 적용했다고 가정하자. 그런데 단어-문서 행렬을 행의 개수가 매우 많다. 어휘 수는 대개 10~20만 개일 것이다. 행렬의 대부분 요소 값은 0이다. 문서 하나에 모든 어휘가 쓰이는 경우는 매우 드물다. 이렇게 대부분의 요소 값이 0인 행렬을 희소 행렬 ** sparse matrix**이라고 한다.
이런 희소 행렬을 다른 모델의 입력값으로 쓰게 되면 계산량도 메모리 소비량도 쓸데없이 커진다. 그래서 원래 행렬의 차원을 축소해 사용한다. 단어와 문서를 기준으로 줄인다.
잠재 의미 분석 행렬 수행 대상 행렬은 여러 종류가 될 수 있다.
TF-IDF 행렬
단어-문맥 행렬
점별 상호 정보량 행렬
최근에는 뉴럴 네트워크 기반의 임베딩 기법들이 주목받고 있다. 이전 단어들이 주어졌을 때 다음 단어가 뭐가 될지 예측하거나 문장 내 일부분에 구멍을 뚫어 놓고 해당 단어가 무엇일지 맞추는 과정에서 학습된다.
1.3.2 단어 수준에서 문장 수준으로
2017년 이전의 임베딩 기법들은 대게 단어 수준 모델이었다. NPLM, Word2Vec, Glove, FastText, Swivel 등이 있다. 단어 수준 임베딩 기법의 단점은 동음이의어 ** homonym을 구분하기 어렵다. 단어 형태가 같다면 동일한 단어로 보고, 문맥 정보를 해당 단어 벡터에 전달하기 때문이다.
다행히도 ELMoEmbeddings from Language Modles**가 발표된 후 문장 수준 임베딩 기법이 주목받았다.
1.3.3 룰 -> 엔드투엔드 -> 프리트레인/파인 튜닝
1990년 : 사람이 피처를 직접 뽑음
2000년 중반 : 딥러닝 모델 주목, 입출력의 관계를 사람의 개입 없이 모델 스스로 처음부터 끝까지 이해하도록 유도
2018년 : 말뭉치로 임베딩을 만듬, 구체적 문제에 맞는 소규모 데이터에 맞게 임베딩을 포함한 모델 전체를 업데이트함
다운스트림 태스크 ** Downstream task**
품사판별 ** Part-of Speech tagging**
개체명 인식 ** Named Entity Recognition**
의미역 분석 ** Semantic Role Labeling**
######예시
품사 판별 : 나는 네가 지난 여름에 한 [일]을 알고 있다. → 일: 명사(Noun)
문장 성분 분석 : 나는 [네가 지난 여름에 한 일]을 알고 있다. → 네가 지난 여름에 한 일 : 명사구(Noun Phrase)
의존 관계 분석 : [자연어 처리는] 늘 그렇듯이 [재미있다]. → 자언어 처리는, 재미있다 : 주격명사구(Nsub)
의미역 분석 : 나는 [네가 지난 여름에 한 일]을 알고 있다. → 네가 지난 여름에 한 일 : 피행위주역(Patient)
상호 참조 해결 : 나는 어제 [성빈이]를 만났다. [그]는 스웨터를 입고 있었다. → 그=성빈이
업스트림 태스크 ** Upstream task**
단어/문장 임베딩을 프리트레인하는 작업
1.3.4 임베딩의 종류와 성능
임베딩 기법
행렬 분해
예측
토픽 기반
행렬 분해 기반 방법
말뭉치 정보가 들어 있는 원래 행렬을 두 개 이상의 작은 행렬로 쪼개는 방식의 임베딩 기법
분해한 이후에 둘 중 하나의 행렬만 쓰거나 둘을 add 하거나 concatenate 임베딩으로 사용
예측 기반 방법
어떤 단어 주변에 특정 단어가 나타날지 예측하거나, 이전 단어들이 주어졌을 때 다음 단어가 무엇일지 예측하거나, 문장 내 일부 단어를 지우고 해당 단어가 무엇일지 맞추는 과정에서 학습
토픽 기반 방법
주어진 문서에 잠재된 주제를 추론** inference**하는 방식으로 임베딩을 수행
모델은 학습이 완료되면 각 문서가 어떤 주제 분포를 갖는지 확률 벡터 형태로 반환 하기 때문에 가능
임베딩 성능 평가
성능 측정 대상 다운스트림 태스크는 형태소 분석, 문장 성분 분석, 의존 관계 분석, 의미역 분석, 상호 참조 해결 등이다.
안타깝겓게도 한국어는 공개된 데이터가 많지 않아 높은 품질 측정을 기대하긴 어렵다.
현업에서는 2013년 구글 연구 팀이 발표한 Word2Vec이라는 기법이 대표적이다.
단어들을 벡터로 바꾸는 방법이다.
한국어 위키백과, KorQuAD, 네이버 영화 리뷰 말뭉치 등은 은전한닢으로 형태소 분석을 한 뒤 100차원으로 학습한 Word2Vec 임베딩 중 희망 이라는 단어의 벡터는 다음과 같다
위 수식의 숫자들은 모두 100개이다. 100차원으로 임베딩을 했기 때문이다.
단어를 벡터로 임베딩하는 순간 단어 벡터들 사이의 유사도 similarity를 계산하는 일이 가능해진다.
각 쿼리 단어별로 벡터 간 유사도 측정 기법의 일종인 코사인 유사도 cosine similarity 기준 상위 4개
희망
절망
학교
학생
소망
체념
초등
대학생
희망찬
절망감
중학교
대학원생
꿈
상실감
야학교
교직원
열망
번민
중학
학부모
희망과 코사인 유사도가 가장 높은 것은 소망이다.
자연어일 때는 불가능했던 코사인 유사도 계산이 임베딩 덕분에 가능해 졌다.
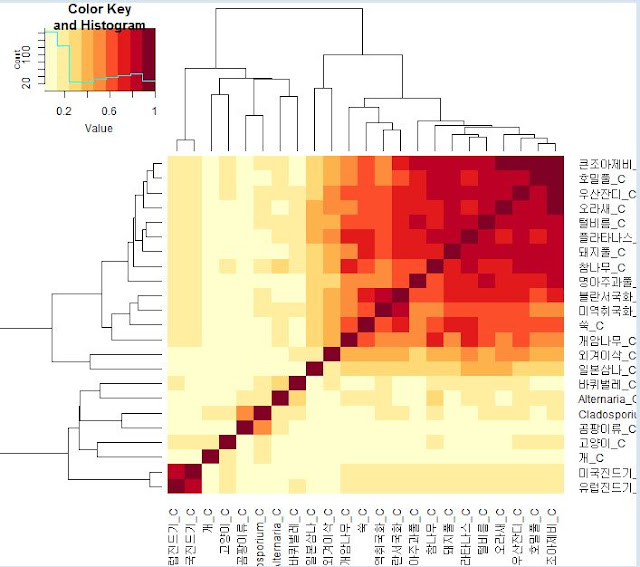
다음은 Word2Vec 임베딩을 통해서 단어 쌍 간 코사인 유사도를 시각화 한 것이다. 검정색일 수록 코사인 유사도가 높다
입베딩을 수행하면 벡터 공간을 기하학적으로 나타낸 시각화 역시 가능하다
1.2.2 의미/문법 정보 함축
입베딩은 벡터인 만큼 사칙연산이 가능하다.
단어 벡터간 덧셈/뺄셈을 통해 단어들 사이의 의미적, 문법적 관계를 도출해낼 수 있다.
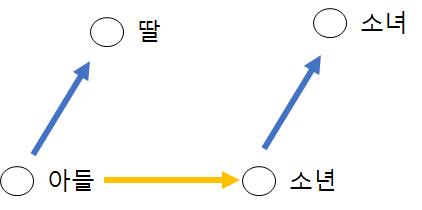
단어 유추 평가 word analogy test
단어1 - 단어2 + 단어3 연산을 수행한 벡터와 코사인 유사도가 가장 높은 단어4를 배열한다
단어1
단어2
단어3
단어4
아들
딸
소년
소녀
아들
딸
아빠
엄마
아들
딸
남성
여성
남동생
여동생
소년
소녀
남동생
여동생
아빠
엄마
1.2.3 전이학습
임베딩은 다른 딥러닝 모델의 입력값으로 자주 쓰인다. 문서 분류를 위한 딥러닝 모델을 만든다.
예컨데 품질 좋은 임베딩을 쓰면 문서 분류 정확도와 학습 속도가 올라간다. 이렇게 임베딩을 다른 딥러닝 모델의 입력값으로 쓰는 기법을 전이 학습 transfer learning 이라고 한다.
전이학습
전이 학습 모델은 제로부터 시작하지 않는다. 대규모 말뭉치를 활용해 임베딩을 미리 만들어 놓는다. 임베딩에는 의미적, 문법적 정보 등이 있다.
문장의 극성을 예측하는 모델
양방향 LSTM에 어텐션 메커니즘을 적용
bidirectional Long Short-Term Memory, Attention
이 딥러닝의 모델의 입력값은 FastText 임베딩(100차원)을 사용했다.
FastText 임베딩은 Word2Vec의 개선된 버전이며 59만 건에 이르는 한국어 문서를 미리 학습한 모델
학습 데이터는 다음과 같다
이 영화 꿀잼 + 긍정 positive
이 영화 노잼 + 부정 negative
전이 학습 모델은 문장을 입력받으면 해당 문장이 긍정인지 부정인지를 출력한다. 문장을 형태소 분석한 뒤 각각의 형태소에 해당하는 FastText 단어 임베딩이 모델의 입력값이 된다.
위의 그래프로 처음 부터 하는 것 보다 FastText 임베딩을 사용한 모델의 성능이 좋다. 즉, 임베딩의 품질이 좋으면 수행하려는 Task의 성능 역시 올라간다.