

Deep Learning
- Neural Network with Many Hidden Layers
- Learning through Back-Propagation from Objective Function (Loss Function)

- 인간의 뇌와 흡사
Type of RNN

빨간색은 input
초록색은 hidden state
파란색은 output
해석하는 형태도 존재
이어져서 뭔가를 한다고 이해하자
Vanilla RNN
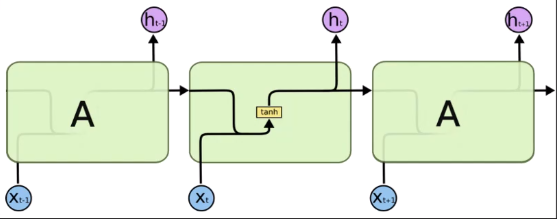
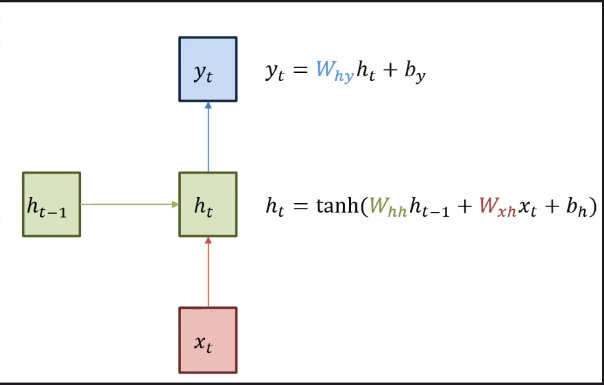
xt와 ht-1을 같이 받는다
Wh는 가중치행렬
- Need to Refine Long Term Dependency
문장길이가 토큰기준 3개정도인데
만약 길이가 길게 되면 최종적 output값에 대해 발생하는 그레디언트 값이 앞쪽까지 전달되는데 문제가 있다.
LSTM (Long Short Term Memory)

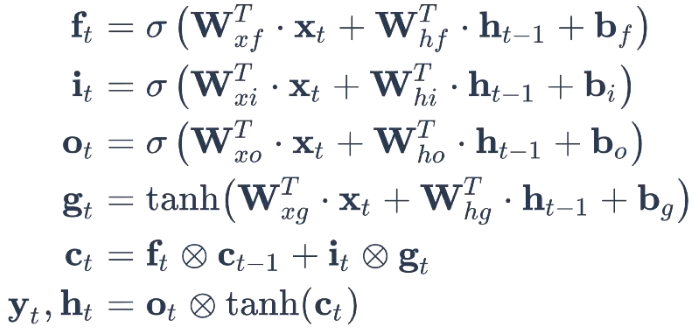
12개의 term이 학습이 된다
Cell state가 있다
xt는 현재시점
t-1은 이전시점
ft는 현재시점에 대한 input과 이전시점에대한 ht-1에 각각 가중치행렬을 곱해주고 b를 더함 이것을 시그모드취해준다.
tanh는 -1 ~ 1 까지임 -> 현재 위치에서 어느정도 정보를 반영할지에 대한 결과
-
forget gate : 현재시점 입력값과 이전시점의 hidden state의 결과에 시그모이드를 취한 값을 이용해서 몇퍼센트 기억할건지 하는 역할
-
input gate : 현재시점 입력값과 이전시점의 hidden state를 tanh를 해서 원소 곱 그리고 forget에서 나온 값과 더한다 -> cell state 업데이트를 함
-
output gate : 업데이트한 cell state를 정보를 바탕으로 output을 통과한 결과에 cell state를 tanh를 해주고 원소 곱 -> ht 와 yt로 내보내줌
GRU(Gated recurrent unit)
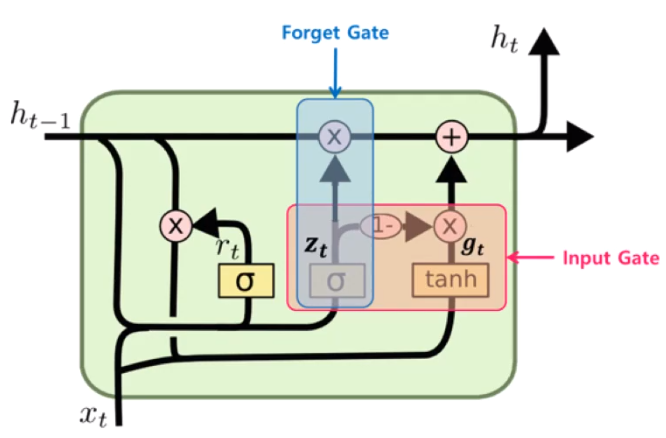
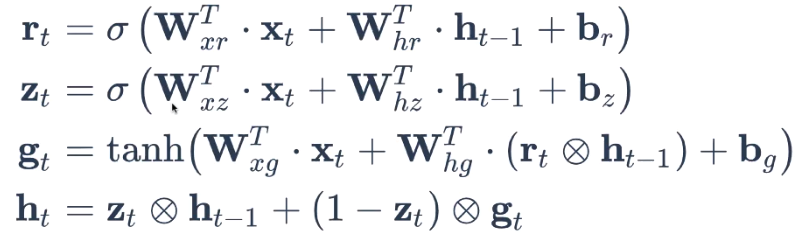
- lstm의 많은 학습을 9개로 줄인 것